Apa Itu File Robots.txt dan Bagaimana Cara Membuatnya (Panduan Pemula)

Daftar Isi
Tahukah Anda bahwa Anda memiliki kendali penuh atas siapa yang merayapi dan mengindeks situs Anda, hingga ke halaman individual?
Cara ini dilakukan melalui file yang disebut Robots.txt.
Robots.txt adalah berkas teks sederhana yang berada di direktori root situs Anda. Berkas ini memberi tahu "robot" (seperti spider mesin pencari) halaman mana yang harus dirayapi di situs Anda, dan halaman mana yang harus diabaikan.
Meskipun tidak penting, file Robots.txt memberi Anda banyak kendali atas bagaimana Google dan mesin pencari lainnya melihat situs Anda.
Jika digunakan dengan benar, hal ini dapat meningkatkan perayapan dan bahkan berdampak pada SEO.
Tetapi bagaimana tepatnya Anda membuat file Robots.txt yang efektif? Setelah dibuat, bagaimana Anda menggunakannya? Dan kesalahan apa yang harus Anda hindari saat menggunakannya?
Dalam posting ini, saya akan membagikan semua yang perlu Anda ketahui tentang file Robots.txt dan cara menggunakannya di blog Anda.
Mari menyelam lebih dalam:
Apa yang dimaksud dengan file Robots.txt?
Pada masa-masa awal internet, para pemrogram dan insinyur menciptakan 'robot' atau 'laba-laba' untuk merayapi dan mengindeks halaman-halaman di web. Robot-robot ini juga dikenal sebagai 'agen-pengguna'.
Terkadang, robot-robot ini akan masuk ke halaman yang tidak ingin diindeks oleh pemilik situs, misalnya, situs yang sedang dibangun atau situs web pribadi.
Untuk mengatasi masalah ini, Martijn Koster, seorang insinyur Belanda yang menciptakan mesin pencari pertama di dunia (Aliweb), mengusulkan seperangkat standar yang harus dipatuhi oleh setiap robot. Standar ini pertama kali diusulkan pada bulan Februari 1994.
Pada tanggal 30 Juni 1994, sejumlah penulis robot dan perintis web awal mencapai konsensus tentang standar.
Standar-standar ini diadopsi sebagai "Protokol Pengecualian Robot" (REP).
File Robots.txt adalah implementasi dari protokol ini.
REP mendefinisikan seperangkat aturan yang harus diikuti oleh setiap perayap atau laba-laba yang sah. Jika Robots.txt menginstruksikan robot untuk tidak mengindeks halaman web, setiap robot yang sah - mulai dari Googlebot hingga MSNbot - harus mengikuti instruksi tersebut.
Catatan: Daftar perayap yang sah dapat ditemukan di sini.
Ingatlah bahwa beberapa robot jahat - malware, spyware, pemanen email, dll. - mungkin tidak mengikuti protokol ini. Inilah sebabnya mengapa Anda mungkin melihat lalu lintas bot di halaman yang telah Anda blokir melalui Robots.txt.
Ada juga robot yang tidak mengikuti standar REP yang tidak digunakan untuk sesuatu yang meragukan.
Anda dapat melihat robots.txt situs web mana pun dengan membuka url ini:
//[domain_website]/robots.txt
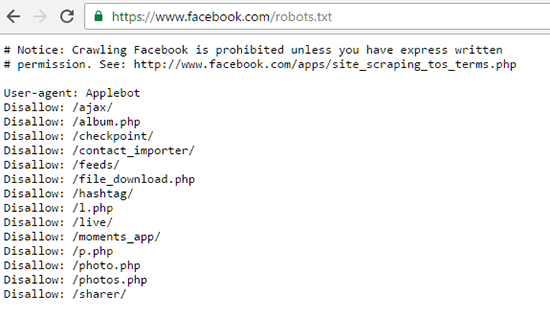
Sebagai contoh, berikut ini adalah file Robots.txt milik Facebook:
Dan inilah file Robots.txt milik Google:

Penggunaan Robots.txt
Robots.txt bukanlah dokumen penting untuk sebuah situs web. Situs Anda bisa mendapatkan peringkat dan berkembang dengan baik tanpa file ini.
Namun, menggunakan Robots.txt memang menawarkan beberapa keuntungan:
- Mencegah bot merayapi folder pribadi - Meskipun tidak sempurna, melarang bot untuk merayapi folder pribadi akan membuat folder tersebut lebih sulit diindeks - setidaknya oleh bot yang sah (seperti spider mesin pencari).
- Mengontrol penggunaan sumber daya - Setiap kali bot merayapi situs Anda, bot menguras bandwidth dan sumber daya server Anda - sumber daya yang lebih baik dihabiskan untuk pengunjung sungguhan. Untuk situs dengan banyak konten, hal ini dapat meningkatkan biaya dan memberikan pengalaman yang buruk bagi pengunjung sungguhan. Anda dapat menggunakan Robots.txt untuk memblokir akses ke skrip, gambar yang tidak penting, dan lain-lain untuk menghemat sumber daya.
- Memprioritaskan halaman penting - Anda ingin spider mesin pencari merayapi halaman-halaman penting di situs Anda (seperti halaman konten), bukannya membuang-buang sumber daya untuk menelusuri halaman-halaman yang tidak berguna (seperti hasil dari kueri penelusuran). Dengan memblokir halaman-halaman yang tidak berguna tersebut, Anda bisa memprioritaskan halaman-halaman mana yang menjadi fokus bot.
Cara menemukan file Robots.txt Anda
Seperti namanya, Robots.txt adalah file teks sederhana.
File ini disimpan di direktori root situs web Anda. Untuk menemukannya, cukup buka alat FTP Anda dan buka direktori situs web Anda di bawah public_html.

Ini adalah file teks yang kecil - milik saya hanya lebih dari 100 byte.
Untuk membukanya, gunakan editor teks apa pun, seperti Notepad. Anda mungkin akan melihat tampilan seperti ini:

Ada kemungkinan Anda tidak akan melihat file Robots.txt di direktori root situs Anda. Dalam kasus ini, Anda harus membuat file Robots.txt sendiri.
Begini caranya:
Cara membuat file Robot.txt
Karena Robots.txt adalah file teks dasar, membuatnya SANGAT mudah - cukup buka editor teks dan simpan file kosong sebagai robots.txt.

Untuk mengunggah berkas ini ke server Anda, gunakan alat FTP favorit Anda (saya sarankan menggunakan WinSCP) untuk masuk ke server web Anda. Kemudian buka folder public_html dan buka direktori root situs Anda.
Tergantung pada bagaimana host web Anda dikonfigurasi, direktori root situs Anda mungkin langsung berada di dalam folder public_html. Atau, mungkin juga sebuah folder di dalamnya.
Setelah direktori root situs Anda terbuka, cukup seret dan letakkan file Robots.txt ke dalamnya.

Sebagai alternatif, Anda dapat membuat file Robots.txt secara langsung dari editor FTP Anda.
Untuk melakukannya, buka direktori root situs Anda dan Klik Kanan - & gt; Buat file baru.
Pada kotak dialog, ketik "robots.txt" (tanpa tanda kutip) dan tekan OK.

Anda akan melihat file robots.txt baru di dalamnya:

Terakhir, pastikan bahwa Anda telah mengatur izin file yang tepat untuk file Robots.txt. Anda ingin pemiliknya - Anda sendiri - untuk membaca dan menulis file tersebut, tetapi tidak untuk orang lain atau publik.
File Robots.txt Anda akan menampilkan "0644" sebagai kode izin.
Jika tidak, klik kanan file Robots.txt Anda dan pilih "Izin file..."

Itu dia - file Robots.txt yang berfungsi penuh!
Tetapi, apa yang sebenarnya dapat Anda lakukan dengan file ini?
Selanjutnya, saya akan menunjukkan kepada Anda beberapa instruksi umum yang dapat Anda gunakan untuk mengontrol akses ke situs Anda.
Cara menggunakan Robots.txt
Ingatlah bahwa Robots.txt pada dasarnya mengontrol bagaimana robot berinteraksi dengan situs Anda.
Ingin memblokir mesin pencari agar tidak dapat mengakses seluruh situs Anda? Cukup ubah izin di Robots.txt.
Ingin memblokir Bing agar tidak mengindeks halaman kontak Anda? Anda juga bisa melakukannya.
Dengan sendirinya, file Robots.txt tidak akan meningkatkan SEO Anda, tetapi Anda bisa menggunakannya untuk mengontrol perilaku perayap di situs Anda.
Untuk menambahkan atau memodifikasi file, cukup buka file tersebut di editor FTP dan tambahkan teks secara langsung. Setelah Anda menyimpan file, perubahan akan langsung terlihat.
Berikut adalah beberapa perintah yang dapat Anda gunakan dalam file Robots.txt Anda:
1. Blokir semua bot dari situs Anda
Ingin memblokir semua robot agar tidak merayapi situs Anda?
Tambahkan kode ini ke file Robots.txt Anda:
Agen pengguna: *Melarang: /
Seperti inilah tampilan file yang sesungguhnya:

Sederhananya, perintah ini memberi tahu setiap agen pengguna (*) untuk tidak mengakses file atau folder apa pun di situs Anda.
Berikut ini penjelasan lengkap tentang apa yang terjadi di sini:
- Agen-pengguna:* - - - - - - - - - Tanda bintang (*) adalah karakter 'wild-card' yang berlaku untuk setiap Jika Anda mencari "*.txt" di komputer Anda, maka akan muncul semua file yang berekstensi .txt. Di sini, tanda bintang berarti perintah Anda berlaku untuk setiap agen-pengguna.
- Melarang: / - "Disallow" adalah perintah robots.txt yang melarang bot merayapi folder. Garis miring tunggal (/) berarti Anda menerapkan perintah ini ke direktori root.
Catatan: Ini sangat ideal jika Anda menjalankan segala jenis situs web pribadi seperti situs keanggotaan. Namun, perlu diketahui bahwa ini akan menghentikan semua bot yang sah seperti Google untuk merayapi situs Anda. Gunakan dengan hati-hati.
2. Blokir semua bot agar tidak mengakses folder tertentu
Bagaimana jika Anda ingin mencegah bot merayapi dan mengindeks folder tertentu?
Misalnya, folder /images?
Gunakan perintah ini:
Agen-pengguna: *Larang: /[nama_folder]/
Jika Anda ingin menghentikan bot agar tidak dapat mengakses folder /images, berikut ini adalah tampilan perintahnya:

Perintah ini berguna jika Anda memiliki folder sumber daya yang tidak ingin dibanjiri dengan permintaan perayap robot, misalnya folder yang berisi skrip yang tidak penting, gambar yang sudah ketinggalan zaman, dan sebagainya.
Catatan: Folder /images hanyalah sebuah contoh. Saya tidak mengatakan bahwa Anda harus memblokir bot agar tidak merayapi folder tersebut. Tergantung apa yang ingin Anda capai.
Mesin pencari biasanya tidak menyukai webmaster yang memblokir bot mereka untuk merayapi folder non-gambar, jadi berhati-hatilah saat Anda menggunakan perintah ini. Saya telah membuat daftar beberapa alternatif untuk Robots.txt untuk menghentikan mesin pencari mengindeks halaman tertentu di bawah ini.
3. Blokir bot tertentu dari situs Anda
Bagaimana jika Anda ingin memblokir robot tertentu - seperti Googlebot - agar tidak dapat mengakses situs Anda?
Inilah perintah untuk itu:
Agen-pengguna: [nama robot]Melarang: /
Misalnya, jika Anda ingin memblokir Googlebot dari situs Anda, inilah yang akan Anda gunakan:

Setiap bot atau agen pengguna yang sah memiliki nama yang spesifik. Laba-laba Google, misalnya, hanya disebut "Googlebot". Microsoft menjalankan "msnbot" dan "bingbot". Bot Yahoo disebut "Yahoo! Slurp".
Untuk menemukan nama-nama yang tepat dari berbagai agen pengguna (seperti Googlebot, bingbot, dll.), gunakan halaman ini.
Catatan: Perintah di atas akan memblokir bot tertentu dari seluruh situs Anda. Googlebot murni digunakan sebagai contoh. Dalam kebanyakan kasus, Anda tidak akan pernah ingin menghentikan Google untuk merayapi situs web Anda. Salah satu kasus penggunaan khusus untuk memblokir bot tertentu adalah untuk menjaga agar bot yang menguntungkan Anda tetap mengunjungi situs Anda, sambil menghentikan bot yang tidak menguntungkan situs Anda.
4. Memblokir file tertentu agar tidak dirayapi
Protokol Pengecualian Robot memberi Anda kontrol yang baik atas file dan folder mana yang ingin Anda blokir aksesnya oleh robot.
Berikut adalah perintah yang dapat Anda gunakan untuk menghentikan file agar tidak dirayapi oleh robot apa pun:
Agen-pengguna: *Larang: /[nama_folder]/[nama_file.extension]
Jadi, jika Anda ingin memblokir file bernama "img_0001.png" dari folder "images", Anda dapat menggunakan perintah ini:

5. Memblokir akses ke folder tetapi mengizinkan file untuk diindeks
Perintah "Larang" memblokir bot agar tidak dapat mengakses folder atau file.
Perintah "Izinkan" melakukan hal yang sebaliknya.
Perintah "Izinkan" menggantikan perintah "Larang" jika perintah sebelumnya menargetkan file individual.
Ini berarti Anda dapat memblokir akses ke sebuah folder namun mengizinkan agen pengguna untuk tetap mengakses file individual di dalam folder tersebut.
Berikut ini format yang digunakan:
Agen-pengguna: *Larang: /[nama_folder]/
Izinkan: /[nama_folder]/[nama_file.extension]/
Sebagai contoh, jika Anda ingin memblokir Google agar tidak merayapi folder "images" tetapi masih ingin memberinya akses ke file "img_0001.png" yang tersimpan di dalamnya, inilah format yang akan Anda gunakan:
Untuk contoh di atas, akan terlihat seperti ini:

Ini akan menghentikan semua halaman di direktori /search/ agar tidak diindeks.
Bagaimana jika Anda ingin menghentikan semua halaman yang cocok dengan ekstensi tertentu (seperti ".php" atau ".png") agar tidak diindeks?
Gunakan ini:
Agen-pengguna: *Larang: /*.extension$
Tanda ($) di sini menandakan akhir URL, yaitu ekstensi adalah string terakhir dalam URL.
Jika Anda ingin memblokir semua halaman dengan ekstensi ".js" (untuk Javascript), inilah yang akan Anda gunakan:

Perintah ini sangat efektif jika Anda ingin menghentikan bot merayapi skrip.
6. Hentikan bot agar tidak merayapi situs Anda terlalu sering
Pada contoh di atas, Anda mungkin pernah melihat perintah ini:
Agen-pengguna: *Penundaan Perayapan: 20
Perintah ini menginstruksikan semua bot untuk menunggu minimal 20 detik di antara permintaan perayapan.
Perintah Crawl-Delay sering digunakan di situs besar dengan konten yang sering diperbarui (seperti Twitter). Perintah ini memberi tahu bot untuk menunggu dalam waktu minimum di antara permintaan berikutnya.
Ini memastikan bahwa server tidak kewalahan dengan terlalu banyak permintaan pada saat yang sama dari bot yang berbeda.
Lihat juga: 15 Tema Basis Pengetahuan & Wiki WordPress Terbaik (Edisi 2023)Sebagai contoh, ini adalah file Robots.txt Twitter yang menginstruksikan bot untuk menunggu minimal 1 detik di antara permintaan:

Anda bahkan dapat mengontrol penundaan perayapan untuk masing-masing bot. Hal ini memastikan bahwa terlalu banyak bot tidak merayapi situs Anda secara bersamaan.
Contohnya, Anda mungkin memiliki serangkaian perintah seperti ini:

Catatan: Anda tidak perlu menggunakan perintah ini kecuali jika Anda menjalankan situs yang sangat besar dengan ribuan halaman baru yang dibuat setiap menitnya (seperti Twitter).
Kesalahan umum yang harus dihindari saat menggunakan Robots.txt
File Robots.txt adalah alat yang ampuh untuk mengendalikan perilaku bot di situs Anda.
Namun, ini juga dapat menyebabkan bencana SEO jika tidak digunakan dengan benar. Ada sejumlah kesalahpahaman tentang Robots.txt yang beredar di dunia maya.
Berikut adalah beberapa kesalahan yang harus Anda hindari saat menggunakan Robots.txt:
Kesalahan #1 - Menggunakan Robots.txt untuk mencegah konten diindeks
Jika Anda "Melarang" sebuah folder di file Robots.txt, bot yang sah tidak akan merayapi folder tersebut.
Namun, ini masih berarti dua hal:
- Bot AKAN merayapi konten folder yang ditautkan dari sumber eksternal. Katakanlah, jika situs lain menautkan ke sebuah file di dalam folder yang diblokir, bot akan mengikutinya dan mengindeksnya.
- Bot jahat - spammer, spyware, malware, dll. - biasanya akan mengabaikan instruksi Robots.txt dan tetap mengindeks konten Anda.
Hal ini membuat Robots.txt menjadi alat yang buruk untuk mencegah konten diindeks.
Lihat juga: 13 Perangkat Lunak Perangkat Lunak Buletin Email Terbaik Untuk Tahun 2023 (Termasuk Opsi Gratis)Inilah yang harus Anda gunakan sebagai gantinya: gunakan tag 'meta noindex'.
Tambahkan tag berikut ini di halaman yang tidak ingin diindeks:
Ini adalah metode yang direkomendasikan, metode yang ramah SEO untuk menghentikan halaman agar tidak diindeks (meskipun masih tidak memblokir spammer).
Catatan: Jika Anda menggunakan plugin WordPress seperti Yoast SEO, atau All in One SEO; Anda dapat melakukan hal ini tanpa mengedit kode apa pun. Sebagai contoh, di plugin Yoast SEO Anda dapat menambahkan tag noindex pada basis per post/halaman seperti ini:

Cukup buka dan posting/halaman dan klik roda gigi di dalam kotak Yoast SEO. Kemudian klik menu tarik-turun di sebelah 'Meta robots index'.
Selain itu, Google akan berhenti mendukung penggunaan "noindex" di file robots.txt mulai tanggal 1 September. Artikel dari SearchEngineLand ini memiliki informasi lebih lanjut.
Kesalahan #2 - Menggunakan Robots.txt untuk melindungi konten pribadi
Jika Anda memiliki konten pribadi - misalnya, PDF untuk kursus email - memblokir direktori melalui file Robots.txt akan membantu, tetapi tidak cukup.
Inilah alasannya:
Konten Anda mungkin masih bisa diindeks jika ditautkan dari sumber eksternal. Selain itu, bot jahat masih akan merayapi konten Anda.
Metode yang lebih baik adalah menyimpan semua konten pribadi di balik login. Ini akan memastikan bahwa tidak ada seorang pun - bot yang sah atau jahat - yang akan mendapatkan akses ke konten Anda.
Kelemahannya adalah ini berarti pengunjung Anda memiliki rintangan ekstra untuk dilewati. Tetapi, konten Anda akan lebih aman.
Kesalahan #3 - Menggunakan Robots.txt untuk menghentikan konten duplikat agar tidak terindeks
Konten duplikat adalah hal yang sangat dilarang dalam hal SEO.
Namun, menggunakan Robots.txt untuk menghentikan konten ini agar tidak diindeks bukanlah solusinya. Sekali lagi, tidak ada jaminan bahwa spider mesin pencari tidak akan menemukan konten ini melalui sumber eksternal.
Berikut ini adalah 3 cara lain untuk menggandakan konten:
- Menghapus konten duplikat - Ini akan menghilangkan konten sepenuhnya. Namun, ini berarti Anda mengarahkan mesin pencari ke 404 halaman - tidak ideal. Karena itu, penghapusan tidak disarankan .
- Gunakan pengalihan 301 - Pengalihan 301 menginstruksikan mesin pencari (dan pengunjung) bahwa sebuah halaman telah dipindahkan ke lokasi baru. Cukup tambahkan pengalihan 301 pada konten duplikat untuk membawa pengunjung ke konten asli Anda.
- Tambahkan tag rel="canonical" - Tag ini merupakan versi 'meta' dari pengalihan 301. Tag "rel=canonical" memberi tahu Google yang merupakan URL asli untuk halaman tertentu, contohnya kode berikut ini:
//example.com/original-page.html "rel="canonical" />
Memberitahu Google bahwa halaman - original-page.html - adalah versi "asli" dari halaman duplikat. Jika Anda menggunakan WordPress, tag ini mudah ditambahkan menggunakan Yoast SEO atau All in One SEO.
Jika Anda ingin pengunjung dapat mengakses konten duplikat, gunakan fitur rel="canonical" Jika Anda tidak ingin pengunjung atau bot mengakses konten - gunakan pengalihan 301.
Berhati-hatilah dalam menerapkan keduanya karena akan berdampak pada SEO Anda.
Untuk Anda
File Robots.txt adalah sekutu yang berguna dalam membentuk cara spider mesin pencari dan bot lainnya berinteraksi dengan situs Anda. Ketika digunakan dengan benar, file ini dapat memberikan efek positif pada peringkat Anda dan membuat situs Anda lebih mudah dirayapi.
Gunakan panduan ini untuk memahami cara kerja Robots.txt, cara pemasangannya, dan beberapa cara umum yang dapat Anda gunakan, serta hindari kesalahan-kesalahan yang telah kita bahas di atas.
Bacaan terkait:
- Alat Pelacakan Peringkat Terbaik Untuk Blogger, Dibandingkan
- Panduan Pasti Untuk Mendapatkan Tautan Situs Google
- 5 Alat Penelitian Kata Kunci yang Kuat Dibandingkan
