Cos'è e come si crea un file Robots.txt (Guida per principianti)

Sommario
Sapevate che avete il controllo completo su chi effettua il crawling e l'indicizzazione del vostro sito, fino alle singole pagine?
Il modo in cui ciò avviene è attraverso un file chiamato Robots.txt.
Robots.txt è un semplice file di testo che si trova nella directory principale del sito e che indica ai "robot" (come gli spider dei motori di ricerca) quali pagine del sito devono essere scansionate e quali ignorate.
Anche se non è essenziale, il file Robots.txt offre un notevole controllo su come Google e gli altri motori di ricerca vedono il vostro sito.
Se usato correttamente, può migliorare il crawling e persino avere un impatto sulla SEO.
Ma come si fa a creare un file Robots.txt efficace? Una volta creato, come si usa e quali sono gli errori da evitare?
In questo post, condividerò tutto ciò che c'è da sapere sul file Robots.txt e su come utilizzarlo sul vostro blog.
Immergiamoci in questa storia:
Che cos'è un file Robots.txt?
Agli albori di Internet, programmatori e ingegneri hanno creato dei "robot" o "spider" per scansionare e indicizzare le pagine del web. Questi robot sono noti anche come "user-agent".
A volte, questi robot si fanno strada su pagine che i proprietari del sito non vogliono che vengano indicizzate, ad esempio un sito in costruzione o un sito web privato.
Per risolvere questo problema, Martijn Koster, un ingegnere olandese che ha creato il primo motore di ricerca al mondo (Aliweb), ha proposto una serie di standard che ogni robot avrebbe dovuto rispettare, proposti per la prima volta nel febbraio 1994.
Il 30 giugno 1994, alcuni autori di robot e pionieri del web hanno raggiunto un consenso sugli standard.
Questi standard sono stati adottati come "Protocollo di esclusione dei robot" (REP).
Il file Robots.txt è un'implementazione di questo protocollo.
Il REP definisce una serie di regole che ogni crawler o spider legittimo deve seguire. Se il Robots.txt indica ai robot di non indicizzare una pagina web, ogni robot legittimo - da Googlebot a MSNbot - deve seguire le istruzioni.
Nota: Un elenco di crawler legittimi è disponibile qui.
Si tenga presente che alcuni robot disonesti - malware, spyware, harvester di e-mail, ecc. - potrebbero non seguire questi protocolli. Ecco perché si potrebbe vedere del traffico bot su pagine bloccate tramite Robots.txt.
Esistono anche robot che non seguono gli standard REP e che non vengono utilizzati per nulla di discutibile.
È possibile vedere il robots.txt di qualsiasi sito web andando a questo indirizzo:
//[dominio_del_sito]/robots.txt
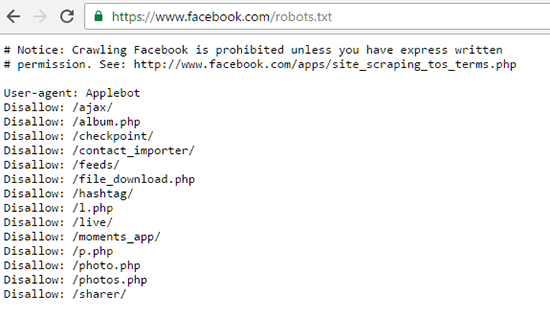
Ad esempio, ecco il file Robots.txt di Facebook:
Ed ecco il file Robots.txt di Google:

Uso di Robots.txt
Il file Robots.txt non è un documento essenziale per un sito web. Il vostro sito può posizionarsi e crescere perfettamente senza questo file.
Tuttavia, l'uso di Robots.txt offre alcuni vantaggi:
- Scoraggiare i bot dal crawling delle cartelle private Anche se non è perfetto, l'esclusione dei bot dal crawling delle cartelle private ne renderà molto più difficile l'indicizzazione, almeno da parte dei bot legittimi (come gli spider dei motori di ricerca).
- Controllo dell'utilizzo delle risorse - Ogni volta che un bot esegue il crawling del vostro sito, consuma la larghezza di banda e le risorse del server, risorse che sarebbero meglio impiegate per i visitatori reali. Per i siti con molti contenuti, questo può far lievitare i costi e dare ai visitatori reali un'esperienza scadente. Potete usare il file Robots.txt per bloccare l'accesso a script, immagini non importanti, ecc. per risparmiare risorse.
- Privilegiare le pagine importanti Si desidera che gli spider dei motori di ricerca effettuino la scansione delle pagine importanti del sito (come le pagine di contenuto), senza sprecare risorse scavando tra le pagine inutili (come i risultati delle query di ricerca). Bloccando queste pagine inutili, è possibile dare priorità alle pagine su cui i bot si concentrano.
Come trovare il vostro file Robots.txt
Come suggerisce il nome, Robots.txt è un semplice file di testo.
Questo file è memorizzato nella directory principale del vostro sito web. Per trovarlo, basta aprire il vostro strumento FTP e navigare nella directory del vostro sito web sotto public_html.

Si tratta di un file di testo molto piccolo: il mio è di poco più di 100 byte.
Per aprirlo, utilizzare un qualsiasi editor di testo, come Notepad. Si può vedere qualcosa di simile a questo:

È possibile che non venga visualizzato alcun file Robots.txt nella directory principale del sito. In questo caso, dovrete creare voi stessi un file Robots.txt.
Ecco come:
Come creare un file Robot.txt
Poiché Robots.txt è un file di testo di base, la sua creazione è MOLTO semplice: basta aprire un editor di testo e salvare un file vuoto come robots.txt.

Per caricare questo file sul vostro server, utilizzate il vostro strumento FTP preferito (vi consiglio di usare WinSCP) per accedere al vostro server web, quindi aprite la cartella public_html e la directory principale del vostro sito.
A seconda di come è configurato il vostro host web, la directory principale del vostro sito potrebbe trovarsi direttamente nella cartella public_html, oppure potrebbe essere una cartella all'interno di questa.
Una volta aperta la directory principale del sito, è sufficiente trascinare il file Robots.txt al suo interno.

In alternativa, è possibile creare il file Robots.txt direttamente dall'editor FTP.
Per farlo, aprire la directory principale del sito e fare clic con il pulsante destro del mouse su -> Crea nuovo file.
Nella finestra di dialogo, digitare "robots.txt" (senza virgolette) e premere OK.

Si dovrebbe vedere un nuovo file robots.txt all'interno:

Infine, assicuratevi di aver impostato i giusti permessi per il file Robots.txt: il proprietario - voi stessi - deve poter leggere e scrivere il file, ma non gli altri o il pubblico.
Il file Robots.txt dovrebbe mostrare "0644" come codice di autorizzazione.
Se non lo fa, fare clic con il tasto destro del mouse sul file Robots.txt e selezionare "Permessi file...".

Ecco a voi un file Robots.txt perfettamente funzionante!
Ma cosa si può fare effettivamente con questo file?
A seguire, vi mostrerò alcune istruzioni comuni che potete utilizzare per controllare l'accesso al vostro sito.
Come utilizzare Robots.txt
Ricordate che il file Robots.txt controlla essenzialmente il modo in cui i robot interagiscono con il vostro sito.
Per bloccare l'accesso dei motori di ricerca all'intero sito, è sufficiente modificare le autorizzazioni nel file Robots.txt.
Volete bloccare l'indicizzazione della vostra pagina di contatto da parte di Bing? Potete fare anche questo.
Di per sé, il file Robots.txt non migliora la SEO, ma può essere utilizzato per controllare il comportamento dei crawler sul sito.
Guarda anche: Come ottenere più seguaci su Twitch: 10 suggerimenti comprovatiPer aggiungere o modificare il file, è sufficiente aprirlo nell'editor FTP e aggiungere direttamente il testo. Una volta salvato il file, le modifiche si rifletteranno immediatamente.
Ecco alcuni comandi da utilizzare nel file Robots.txt:
1. Bloccate tutti i bot dal vostro sito
Volete bloccare tutti i robot dal crawling del vostro sito?
Aggiungete questo codice al vostro file Robots.txt:
User-agent: *Disallow: /
Questo è l'aspetto del file reale:

In parole povere, questo comando indica a ogni user agent (*) di non accedere a nessun file o cartella del vostro sito.
Ecco la spiegazione completa di ciò che sta accadendo esattamente:
- User-agent:* - L'asterisco (*) è un carattere "jolly" che si applica a ogni (come il nome di un file o, in questo caso, di un bot). Se si cerca "*.txt" sul proprio computer, verranno visualizzati tutti i file con estensione .txt. In questo caso, l'asterisco significa che il comando si applica a ogni user-agent.
- Disallow: / - "Disallow" è un comando robots.txt che vieta a un bot di effettuare il crawling di una cartella. Il singolo slash in avanti (/) significa che il comando viene applicato alla directory principale.
Nota: È l'ideale se gestite un sito web privato, come ad esempio un sito associativo. Ma sappiate che in questo modo tutti i bot legittimi, come ad esempio Google, non potranno più effettuare il crawling del vostro sito. Usatelo con cautela.
2. Bloccare tutti i bot dall'accesso a una cartella specifica.
E se si volesse impedire ai bot di effettuare il crawling e l'indicizzazione di una cartella specifica?
Ad esempio, la cartella /images?
Utilizzare questo comando:
Agente utente: *Disallow: /[nome_cartella]/
Se si vuole impedire ai bot di accedere alla cartella /images, ecco come si presenterebbe il comando:

Questo comando è utile se si dispone di una cartella di risorse che non si vuole sovraccaricare di richieste da parte dei robot crawler. Può trattarsi di una cartella con script non importanti, immagini obsolete, ecc.
Nota: La cartella /images è solo un esempio. Non sto dicendo che si debba bloccare ai bot la possibilità di strisciare quella cartella. Dipende da ciò che si sta cercando di ottenere.
I motori di ricerca di solito non vedono di buon occhio i webmaster che bloccano i loro bot dal crawling di cartelle non di immagini, quindi fate attenzione quando usate questo comando. Di seguito ho elencato alcune alternative a Robots.txt per impedire ai motori di ricerca di indicizzare pagine specifiche.
3. Bloccare bot specifici dal vostro sito
E se si volesse bloccare l'accesso al sito a un robot specifico, come Googlebot?
Ecco il relativo comando:
User-agent: [nome del robot]Disallow: /
Ad esempio, se si volesse bloccare Googlebot dal proprio sito, si utilizzerebbe questo:

Ogni bot o user-agent legittimo ha un nome specifico. Lo spider di Google, ad esempio, si chiama semplicemente "Googlebot", Microsoft gestisce sia "msnbot" che "bingbot", mentre il bot di Yahoo si chiama "Yahoo! Slurp".
Per trovare i nomi esatti dei diversi user-agent (come Googlebot, bingbot, ecc.) utilizzate questa pagina.
Nota: Il comando di cui sopra blocca un bot specifico dall'intero sito. Googlebot è utilizzato a titolo puramente esemplificativo. Nella maggior parte dei casi non si vuole mai impedire a Google di effettuare il crawling del proprio sito web. Un caso d'uso specifico per il blocco di bot specifici è quello di far sì che i bot che vi avvantaggiano arrivino sul vostro sito e di bloccare quelli che non ne beneficiano.
4. Bloccare un file specifico per impedirne il crawling
Il Protocollo di esclusione dei robot consente di controllare con precisione i file e le cartelle a cui si desidera bloccare l'accesso ai robot.
Ecco il comando che si può usare per impedire che un file venga strisciato da qualsiasi robot:
Agente utente: *Disallow: /[nome_cartella]/[nome_file.estensione]
Quindi, se si vuole bloccare un file chiamato "img_0001.png" dalla cartella "images", si usa questo comando:

5. Bloccare l'accesso a una cartella ma consentire l'indicizzazione di un file.
Il comando "Disallow" blocca l'accesso dei bot a una cartella o a un file.
Il comando "Consenti" fa il contrario.
Il comando "Consenti" sostituisce il comando "Disconosci" se il primo è rivolto a un singolo file.
Ciò significa che è possibile bloccare l'accesso a una cartella, ma consentire agli utenti-agenti di accedere a un singolo file all'interno della cartella.
Ecco il formato da utilizzare:
Agente utente: *Disallow: /[nome_cartella]/
Consenti: /[nome_cartella]/[nome_file.estensione]/
Ad esempio, se si vuole bloccare Google dal crawling della cartella "images", ma si vuole comunque dare accesso al file "img_0001.png" in essa contenuto, ecco il formato da utilizzare:
Per l'esempio di cui sopra, l'aspetto è il seguente:

In questo modo tutte le pagine della directory /search/ non saranno indicizzate.
E se si volesse impedire che tutte le pagine che corrispondono a un'estensione specifica (come ".php" o ".png") vengano indicizzate?
Utilizzare questo:
Agente utente: *Disallow: /*.extension$
Il segno ($) indica la fine dell'URL, cioè l'estensione è l'ultima stringa dell'URL.
Se si volesse bloccare tutte le pagine con estensione ".js" (per Javascript), ecco cosa si dovrebbe usare:

Questo comando è particolarmente efficace se si vuole impedire ai bot di eseguire il crawling degli script.
6. Impedire ai bot di effettuare il crawling del vostro sito troppo frequentemente
Negli esempi precedenti, potreste aver visto questo comando:
Agente utente: *Ritardo di strisciamento: 20
Questo comando indica a tutti i bot di attendere un minimo di 20 secondi tra le richieste di crawling.
Il comando Crawl-Delay è usato frequentemente su siti di grandi dimensioni con contenuti aggiornati di frequente (come Twitter). Questo comando indica ai bot di attendere un tempo minimo tra le richieste successive.
In questo modo si garantisce che il server non venga sovraccaricato da troppe richieste contemporaneamente da parte di bot diversi.
Ad esempio, questo è il file Robots.txt di Twitter che indica ai bot di attendere almeno 1 secondo tra una richiesta e l'altra:

È anche possibile controllare il ritardo di crawl per i singoli bot, in modo da evitare che troppi bot effettuino il crawling del sito contemporaneamente.
Ad esempio, si potrebbe avere un insieme di comandi come questo:

Nota: Non è necessario usare questo comando, a meno che non si gestisca un sito enorme con migliaia di nuove pagine create ogni minuto (come Twitter).
Errori comuni da evitare quando si usa il file Robots.txt
Il file Robots.txt è un potente strumento per controllare il comportamento dei bot sul vostro sito.
Tuttavia, se non viene utilizzato correttamente, può anche portare a un disastro a livello di SEO. Non aiuta il fatto che ci siano diverse idee sbagliate su Robots.txt che circolano in rete.
Ecco alcuni errori da evitare quando si utilizza il file Robots.txt:
Errore n. 1 - Usare il file Robots.txt per impedire l'indicizzazione dei contenuti
Se si "disconosce" una cartella nel file Robots.txt, i bot legittimi non la scorreranno.
Ma questo significa comunque due cose:
- I bot effettueranno il crawling dei contenuti della cartella collegati da fonti esterne. Ad esempio, se un altro sito rimanda a un file all'interno della cartella bloccata, i bot lo seguiranno e lo indicizzeranno.
- I bot illegali - spammer, spyware, malware, ecc. - di solito ignorano le istruzioni di Robots.txt e indicizzano i vostri contenuti a prescindere.
Questo rende il Robots.txt uno strumento inadeguato per impedire l'indicizzazione dei contenuti.
Ecco cosa usare al suo posto: utilizzare il tag "meta noindex".
Aggiungete il seguente tag nelle pagine che non volete siano indicizzate:
Questo è il metodo consigliato e SEO-friendly per impedire che una pagina venga indicizzata (anche se non blocca gli spammer).
Nota: Se utilizzate un plugin di WordPress come Yoast SEO o All in One SEO, potete farlo senza modificare il codice. Ad esempio, nel plugin Yoast SEO potete aggiungere il tag noindex per ogni post/pagina in questo modo:

È sufficiente aprire un post/pagina e fare clic sull'ingranaggio all'interno del riquadro di Yoast SEO, quindi fare clic sul menu a tendina accanto a "Meta robots index".
Inoltre, Google smetterà di supportare l'uso di "noindex" nei file robots.txt a partire dal 1° settembre. Questo articolo di SearchEngineLand contiene ulteriori informazioni.
Errore n. 2 - Utilizzare Robots.txt per proteggere i contenuti privati
Se avete contenuti privati, ad esempio i PDF di un corso via e-mail, il blocco della directory tramite il file Robots.txt vi aiuterà, ma non è sufficiente.
Ecco perché:
Guarda anche: Cornerstone Content: come sviluppare una strategia di contenuti vincenteIl vostro contenuto potrebbe comunque essere indicizzato se viene linkato da fonti esterne. Inoltre, i bot malintenzionati continueranno a scansionarlo.
Un metodo migliore è quello di mantenere tutti i contenuti privati dietro un login, in modo da garantire che nessuno - bot legittimi o malintenzionati - possa accedere ai vostri contenuti.
Il rovescio della medaglia è che i vostri visitatori dovranno fare un salto in più, ma i vostri contenuti saranno più sicuri.
Errore n. 3 - Usare Robots.txt per impedire che i contenuti duplicati vengano indicizzati
I contenuti duplicati sono un grande no quando si tratta di SEO.
Tuttavia, l'utilizzo di Robots.txt per impedire l'indicizzazione di questi contenuti non è la soluzione. Ancora una volta, non c'è alcuna garanzia che gli spider dei motori di ricerca non trovino questi contenuti attraverso fonti esterne.
Ecco altri 3 modi per gestire i contenuti duplicati:
- Eliminare i contenuti duplicati - In questo modo si elimina completamente il contenuto, ma ciò significa che si portano i motori di ricerca su pagine 404, il che non è ideale. Per questo motivo, la cancellazione non è consigliata .
- Utilizzare il reindirizzamento 301 - Un reindirizzamento 301 indica ai motori di ricerca (e ai visitatori) che una pagina è stata spostata in una nuova posizione. È sufficiente aggiungere un reindirizzamento 301 ai contenuti duplicati per portare i visitatori ai contenuti originali.
- Aggiungere il tag rel="canonical - Questo tag è una versione "meta" del reindirizzamento 301. Il tag "rel=canonical" indica a Google l'URL originale di una determinata pagina. Ad esempio questo codice:
//example.com/original-page.html " rel="canonical" />
Indica a Google che la pagina - original-page.html - è la versione "originale" della pagina duplicata. Se utilizzate WordPress, questo tag è facile da aggiungere utilizzando Yoast SEO o All in One SEO.
Se si vuole che i visitatori possano accedere al contenuto duplicato, utilizzare l'opzione rel="canonico" Se non si vuole che i visitatori o i bot accedano ai contenuti, utilizzare un reindirizzamento 301.
Fate attenzione all'implementazione di entrambi perché avranno un impatto sulla vostra SEO.
A voi la parola
Il file Robots.txt è un utile alleato per modellare il modo in cui gli spider dei motori di ricerca e altri bot interagiscono con il vostro sito. Se usato correttamente, può avere un effetto positivo sulle vostre classifiche e rendere il vostro sito più facile da scansionare.
Utilizzate questa guida per capire come funziona il file Robots.txt, come si installa e come si usa comunemente, evitando gli errori di cui abbiamo parlato sopra.
Lettura correlata:
- I migliori strumenti di monitoraggio delle classifiche per i blogger a confronto
- La guida definitiva per ottenere i sitelink di Google
- 5 potenti strumenti per la ricerca di parole chiave a confronto
