什么是Robots.txt文件? 如何创建? (初学者指南)
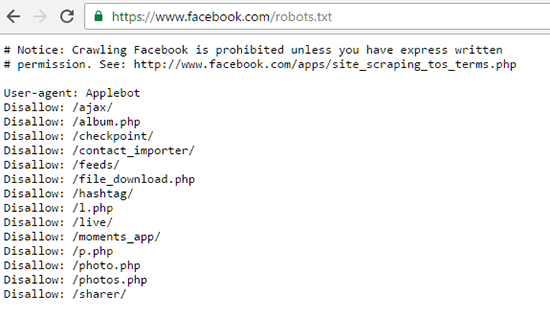

Table of contents
你知道吗,你可以完全控制谁来抓取和索引你的网站,甚至是单个页面?
这种方式是通过一个叫做Robots.txt的文件来实现的。
Robots.txt是一个简单的文本文件,位于你的网站的根目录中。 它告诉 "机器人"(如搜索引擎蜘蛛)在你的网站上要抓取哪些页面,哪些页面要被忽略。
虽然不是必须的,但Robots.txt文件让你对谷歌和其他搜索引擎如何看待你的网站有很多控制。
如果使用得当,这可以改善爬行,甚至影响SEO。
但是,你究竟如何创建一个有效的Robots.txt文件? 一旦创建,你如何使用它? 以及在使用它时,你应该避免哪些错误?
在这篇文章中,我将分享你需要知道的关于Robots.txt文件的一切,以及如何在你的博客上使用它。
让我们深入了解一下:
什么是Robots.txt文件?
早在互联网的早期,程序员和工程师创造了'机器人'或'蜘蛛'来抓取和索引网络上的页面。 这些机器人也被称为'用户代理'。
有时,这些机器人会进入网站所有者不希望被索引的页面。 例如,一个正在建设的网站或私人网站。
为了解决这个问题,创建了世界上第一个搜索引擎(Aliweb)的荷兰工程师Martijn Koster提出了一套每个机器人都必须遵守的标准。 这些标准是在1994年2月首次提出。
1994年6月30日,一些机器人作者和早期的网络先驱者就标准达成了共识。
这些标准被采纳为 "机器人排除协议"(REP)。
Robots.txt文件是该协议的一个实现。
REP定义了一套每一个合法的爬虫或蜘蛛都必须遵守的规则。 如果Robots.txt指示机器人不要索引一个网页,每一个合法的机器人--从Googlebot到MSNbot--都必须遵守该指示。
请注意: 合法爬虫的名单可以在这里找到。
请记住,一些流氓机器人--恶意软件、间谍软件、电子邮件收割机等--可能不遵守这些协议。 这就是为什么你可能在你通过Robots.txt封锁的网页上看到机器人的流量。
还有一些不遵循REP标准的机器人,并没有用于任何有问题的事情。
你可以通过访问这个网址查看任何网站的robots.txt:
//[site_domain]/robots.txt
例如,这里是Facebook的Robots.txt文件:
而这里是谷歌的Robots.txt文件:

使用Robots.txt
Robots.txt不是一个网站的必要文件。 没有这个文件,你的网站也可以有很好的排名和发展。
然而,使用Robots.txt确实有一些好处:
- 阻止机器人抓取私人文件夹----。 虽然不是很完美,但不允许机器人抓取私人文件夹将使它们更难被索引--至少是被合法的机器人(如搜索引擎蜘蛛)索引。
- 控制资源的使用 - 每次机器人抓取你的网站,都会消耗你的带宽和服务器资源--这些资源可以更好地用于真正的访问者。 对于有大量内容的网站,这可能会增加成本,并给真正的访问者带来糟糕的体验。 你可以使用Robots.txt来阻止对脚本、不重要的图像等的访问,以节约资源。
- 优先处理重要的页面 - 你希望搜索引擎蜘蛛能抓取你网站上的重要页面(如内容页),而不是浪费资源去挖掘无用的页面(如搜索查询的结果)。 通过阻止这些无用的页面,你可以优先考虑机器人关注的页面。
如何找到你的Robots.txt文件
顾名思义,Robots.txt是一个简单的文本文件。
这个文件存储在你的网站的根目录下,要找到它,只需打开你的FTP工具,导航到你的网站目录public_html下。

这是一个很小的文本文件--我的只有100多字节。
要打开它,使用任何文本编辑器,如记事本。 你可能会看到类似这样的东西:

你有可能在你的网站根目录中看不到任何Robots.txt文件。 在这种情况下,你必须自己创建一个Robots.txt文件。
下面是方法:
如何创建Robot.txt文件
由于Robots.txt是一个基本的文本文件,创建它非常简单--只需打开一个文本编辑器并保存一个空文件为Robots.txt。

要把这个文件上传到你的服务器,使用你最喜欢的FTP工具(我推荐使用WinSCP)登录到你的网络服务器。 然后打开public_html文件夹,并打开你的网站根目录。
根据你的虚拟主机的配置方式,你的网站根目录可能直接在public_html文件夹内。 或者,它可能是其中的一个文件夹。
一旦你打开了你网站的根目录,只需将Robots.txt文件拖到其中。

或者,你可以直接从你的FTP编辑器创建Robots.txt文件。
要做到这一点,打开你的网站根目录,右击->创建新文件。
在对话框中,输入 "robots.txt"(不带引号),然后点击确定。

你应该看到里面有一个新的 robots.txt 文件:

最后,确保你已经为Robots.txt文件设置了正确的文件权限。你希望文件的所有者--你自己--能够阅读和写入该文件,但不能向其他人或公众开放。
你的Robots.txt文件应该显示 "0644 "作为权限代码。
如果没有,右击你的Robots.txt文件,选择 "文件权限"。

你有了它--一个功能齐全的Robots.txt文件!
但是,你实际上可以用这个文件做什么?
接下来,我将向你展示一些常见的指令,你可以用来控制对你网站的访问。
如何使用Robots.txt
请记住,Robots.txt本质上是控制机器人如何与你的网站互动。
想阻止搜索引擎访问你的整个网站? 只需改变Robots.txt中的权限。
想阻止Bing对你的联系页面进行索引吗? 你也可以这样做。
就其本身而言,Robots.txt文件不会改善你的SEO,但你可以用它来控制你网站上的爬行者行为。
要添加或修改文件,只需在FTP编辑器中打开,并直接添加文本。 一旦你保存文件,变化将立即反映出来。
这里有一些命令,你可以在你的Robots.txt文件中使用:
1.阻止所有机器人进入你的网站
想阻止所有机器人抓取您的网站吗?
将此代码添加到你的Robots.txt文件中:
See_also: 2023年的10个最佳YouTube替代品(比较)用户代理:不允许: /
这就是它在实际文件中的样子:

简单地说,这个命令告诉每个用户代理(*)不要访问你网站上的任何文件或文件夹。
以下是对这里到底发生了什么的完整解释:
- 用户-代理:* - 星号(*)是一个 "通配符 "字符,适用于 每一个 如果你在你的电脑上搜索 "*.txt",它将显示每一个以.txt为扩展名的文件。 这里,星号意味着你的命令适用于 每一个 user-agent。
- 不允许: / - "禁止 "是一个Robots.txt命令,禁止机器人抓取一个文件夹。 单一的正斜杠(/)意味着你要把这个命令应用到根目录。
请注意: 如果你经营任何类型的私人网站,如会员制网站,这是理想的选择。 但要注意,这将阻止所有合法的机器人,如谷歌抓取你的网站。 请谨慎使用。
2.阻止所有机器人访问一个特定的文件夹
如果你想阻止机器人抓取和索引一个特定的文件夹,怎么办?
例如,/images文件夹?
使用此命令:
用户-代理: *不允许:/[folder_name]/
如果你想阻止机器人访问/images文件夹,下面是命令的样子:

如果你有一个不想被机器人爬虫请求淹没的资源文件夹,这个命令很有用。 这可以是一个包含不重要的脚本、过时的图片等的文件夹。
请注意: /images文件夹纯粹是一个例子。 我并不是说你应该阻止机器人抓取该文件夹。 这取决于你想要实现什么。
搜索引擎通常不喜欢网站管理员阻止他们的机器人抓取非图片文件夹,所以在使用这个命令时要小心。 我在下面列出了一些Robots.txt的替代品,用于阻止搜索引擎对特定网页进行索引。
3.阻止特定机器人进入你的网站
如果你想阻止一个特定的机器人--如Googlebot--访问你的网站,怎么办?
下面是它的命令:
用户-代理:[机器人名称]不允许: /
例如,如果你想阻止谷歌机器人进入你的网站,这就是你要使用的方法:

每个合法的机器人或用户代理都有一个特定的名字。 例如,谷歌的蜘蛛被简单地称为 "Googlebot"。 微软同时运行 "msnbot "和 "bingbot"。 雅虎的机器人被称为 "雅虎Slurp"。
要找到不同的用户代理(如Googlebot、bingbot等)的确切名称,请使用这个页面。
请注意: 上述命令将阻止一个特定的机器人进入你的整个网站。 Googlebot纯粹是作为一个例子。 在大多数情况下,你永远不会想阻止Google抓取你的网站。 阻止特定机器人的一个特定用例是让那些有利于你的机器人进入你的网站,同时阻止那些对你的网站没有好处的机器人。
4.阻止一个特定文件被抓取
机器人排除协议使你能够精细控制你想阻止机器人访问的文件和文件夹。
下面是你可以用来阻止一个文件被任何机器人抓取的命令:
用户-代理: *禁止:/[文件夹名称]/[文件名.扩展名]
因此,如果你想从 "images "文件夹中屏蔽一个名为 "img_0001.png "的文件,你会使用这个命令:

5.阻止对一个文件夹的访问,但允许对一个文件进行索引
禁止 "命令阻止机器人访问一个文件夹或一个文件。
而 "允许 "命令的作用正好相反。
如果 "允许 "命令针对的是单个文件,那么 "允许 "命令将取代 "不允许 "命令。
这意味着你可以阻止对一个文件夹的访问,但允许用户代理仍然可以访问该文件夹中的单个文件。
以下是要使用的格式:
用户-代理: *不允许:/[folder_name]/
允许:/[folder_name]/[file_name.extension]/。
例如,如果你想阻止谷歌抓取 "images "文件夹,但仍想让它访问存储在其中的 "img_0001.png "文件,这里是你要使用的格式:
对于上述例子,它看起来像这样:

这将阻止/search/目录中的所有页面被索引。
如果你想阻止所有符合特定扩展名(如".php "或".png")的网页被索引,会怎么样?
使用这个:
用户-代理: *不允许:/*.extension$
这里的($)符号表示URL的结束,即扩展名是URL的最后一个字符串。
如果你想阻止所有带有".js "扩展名(代表Javascript)的页面,你会用以下方法:

如果你想阻止机器人抓取脚本,这个命令就特别有效。
6.阻止机器人过于频繁地抓取你的网站
在上面的例子中,你可能已经看到了这个命令:
用户-代理: *抓取-延迟:20
该命令指示所有机器人在抓取请求之间至少等待20秒。
Crawl-Delay命令经常用于内容经常更新的大型网站(如Twitter)。 该命令告诉机器人在后续请求之间等待一个最小的时间。
这可以确保服务器不会被来自不同机器人的太多请求所淹没。
例如,这是Twitter的Robots.txt文件,指示机器人在两次请求之间至少等待1秒:

您甚至可以控制单个机器人的抓取延迟。 这可以确保太多的机器人不会同时抓取您的网站。
例如,你可能有一组这样的命令:

请注意: 你不会真的需要使用这个命令,除非你正在运行一个大规模的网站,每分钟都有成千上万的新页面被创建(如Twitter)。
使用Robots.txt时应避免的常见错误
Robots.txt文件是控制机器人在你网站上行为的一个强大工具。
然而,如果使用不当,它也可能导致SEO灾难。 网上流传着许多关于Robots.txt的误解,这也无济于事。
这里有一些你在使用Robots.txt时必须避免的错误:
错误#1 - 使用Robots.txt防止内容被索引
如果你在Robots.txt文件中 "禁止 "一个文件夹,合法的机器人就不会抓取它。
但是,这仍然意味着两件事:
- 机器人会抓取从外部来源链接的文件夹的内容。 例如,如果另一个网站链接到你封锁的文件夹中的一个文件,机器人会跟踪并索引它。
- 流氓机器人--垃圾邮件发送者、间谍软件、恶意软件等--通常会忽略Robots.txt的指示,不管不顾地索引你的内容。
这使得Robots.txt成为防止内容被索引的糟糕工具。
以下是你应该使用的替代方法:使用 "元无索引 "标签。
在你不希望被索引的页面中添加以下标签:
这是推荐的、有利于SEO的方法,可以阻止一个页面被索引(尽管它仍然不能阻止垃圾邮件)。
请注意: 如果你使用WordPress插件,如Yoast SEO,或All in One SEO;你可以在不编辑任何代码的情况下做到这一点。 例如,在Yoast SEO插件中,你可以像这样在每个帖子/页面上添加noindex标签:

只要打开帖子/页面,点击Yoast SEO框内的齿轮。 然后点击 "Meta robots index "旁边的下拉菜单。
此外,谷歌将从9月1日起停止支持在robots.txt文件中使用 "noindex"。 SearchEngineLand的这篇文章有更多信息。
错误2 - 使用Robots.txt来保护私人内容
如果你有私人内容--例如,电子邮件课程的PDF--通过Robots.txt文件封锁目录会有帮助,但这还不够。
原因就在这里:
如果你的内容是从外部来源链接的,它仍然可能被索引。 此外,流氓机器人仍然会抓取它。
一个更好的方法是将所有的私人内容保存在一个登录名后面。 这将确保没有人--合法的或流氓的机器人--会得到你的内容。
缺点是,这确实意味着你的访客要多跳一个圈。 但是,你的内容将更加安全。
错误3 - 使用Robots.txt来阻止重复内容被索引
当涉及到SEO时,重复的内容是一个大禁忌。
然而,使用Robots.txt来阻止这些内容被索引并不是解决办法。 再一次,不能保证搜索引擎蜘蛛不会通过外部来源找到这些内容。
以下是处理重复内容的其他3种方法:
- 删除重复的内容 - 这将完全摆脱内容。 然而,这意味着你将搜索引擎引向404页--并不理想。 因为这一点、 不建议删除 .
- 使用301重定向 - 301重定向指示搜索引擎(和访问者),一个页面已经转移到一个新的位置。 只需在重复的内容上添加一个301重定向,将访问者带到你的原始内容。
- 添加rel="canonical "标签 - 这个标签是301重定向的 "元 "版本。 rel=canonical "标签告诉谷歌哪个是特定页面的原始URL。 例如这个代码:
//example.com/original-page.html " rel="canonical" />;
如果你使用WordPress,这个标签很容易使用Yoast SEO或All in One SEO来添加,它是重复页面的 "原始 "版本。
See_also: 2023年7个最好的Gleam替代品的比较
如果你想让访问者能够访问重复的内容,使用 rel="canonical" 如果你不想让访客或机器人访问内容--使用301重定向。
要小心实施这两种方法,因为它们会影响你的SEO。
移交给你
Robots.txt文件是塑造搜索引擎蜘蛛和其他机器人与你的网站互动方式的一个有用的盟友。 如果使用得当,它们可以对你的排名产生积极影响,使你的网站更容易被抓取。
使用本指南了解Robots.txt如何工作,如何安装以及一些常见的使用方法。 并避免我们上面讨论的任何错误。
相关阅读:
- 博客的最佳排名跟踪工具,比较一下
- 获得谷歌网站链接的权威指南
- 5个强大的关键词研究工具的比较
