Kas ir Robots.txt fails un kā to izveidot? (Rokasgrāmata iesācējiem)

Satura rādītājs
Vai zinājāt, ka jums ir pilnīga kontrole pār to, kas pārlūko un indeksē jūsu vietni, līdz pat atsevišķām lapām?
Tas tiek darīts, izmantojot failu Robots.txt.
Robots.txt ir vienkāršs teksta fails, kas atrodas jūsu vietnes saknes direktorijā. Tas norāda "robotiem" (piemēram, meklētājprogrammu zirnekļiem), kuras lapas jūsu vietnē pārmeklēt un kuras lapas ignorēt.
Lai gan tas nav būtiski, Robots.txt fails ļauj jums lielā mērā kontrolēt to, kā Google un citas meklētājprogrammas redz jūsu vietni.
Ja to izmanto pareizi, tas var uzlabot pārlūkošanu un pat ietekmēt SEO.
Bet kā tieši izveidot efektīvu Robots.txt failu? Kā to izmantot, kad tas ir izveidots? Un no kādām kļūdām jāizvairās, to izmantojot?
Šajā rakstā es dalīšos ar visu, kas jums jāzina par Robots.txt failu un kā to izmantot savā blogā.
Iegremdēsimies:
Kas ir Robots.txt fails?
Interneta pirmsākumos programmētāji un inženieri izveidoja "robotus" jeb "zirnekļus", kas pārlūkoja un indeksēja lapas tīmeklī. Šos robotus dēvē arī par "lietotāja aģentiem".
Dažreiz šie roboti iekļūst lapās, kuras vietņu īpašnieki nevēlas indeksēt, piemēram, veidojamajās vietnēs vai privātajās vietnēs.
Lai atrisinātu šo problēmu, holandiešu inženieris Martijns Kosters, kurš izveidoja pasaulē pirmo meklētājprogrammu (Aliweb), ierosināja standartu kopumu, kas būtu jāievēro katram robotam. Šie standarti pirmo reizi tika ierosināti 1994. gada februārī.
1994. gada 30. jūnijā vairāki robotu autori un pirmie tīmekļa pionieri panāca vienprātību par standartiem.
Šie standarti tika pieņemti kā "Robotu izslēgšanas protokols" (REP).
Robots.txt fails ir šī protokola implementācija.
REP nosaka noteikumu kopumu, kas jāievēro katram leģitīmam rāpotājam vai zirneklim. Ja Robots.txt uzdod robotiem neindeksēt tīmekļa lapu, katram leģitīmam robotam - no Googlebot līdz MSNbot - ir jāievēro šie norādījumi.
Piezīme: Leģitīmu pārlūkošanas programmu sarakstu var atrast šeit.
Paturiet prātā, ka daži negodīgi roboti - ļaunprātīga programmatūra, spiegprogrammatūra, e-pasta savācēji u. c. - var neievērot šos protokolus. Tāpēc jūs varat redzēt robotu datplūsmu lapās, kuras esat bloķējis, izmantojot Robots.txt.
Ir arī roboti, kas neatbilst REP standartiem un netiek izmantoti nekādiem apšaubāmiem mērķiem.
Jebkuras vietnes robots.txt var apskatīt, apmeklējot šo url adresi:
//[website_domain]/robots.txt
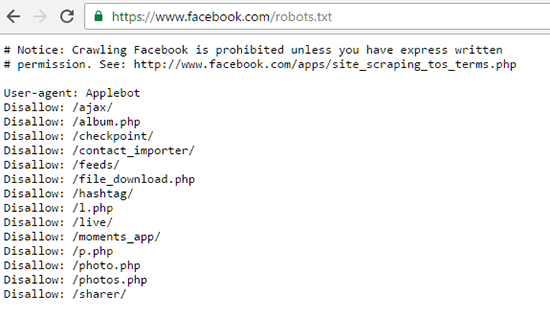
Piemēram, šeit ir Facebook Robots.txt fails:
Un šeit ir Google Robots.txt fails:

Robots.txt izmantošana
Robots.txt nav būtisks tīmekļa vietnes dokuments. Jūsu vietne var lieliski ierindoties un attīstīties arī bez šī faila.
Tomēr Robots.txt izmantošana sniedz dažas priekšrocības:
- Atturēt botus no privāto mapju pārlūkošanas - Lai gan tas nav ideāli, tomēr, aizliedzot botiem pārmeklēt privātās mapes, būs daudz grūtāk tās indeksēt - vismaz likumīgiem robotiem (piemēram, meklēšanas sistēmu zirnekļiem).
- Resursu izmantošanas kontrole - Katru reizi, kad robots pārlūko jūsu vietni, tas iztukšo joslas platumu un servera resursus - resursus, kurus labāk izmantot reāliem apmeklētājiem. Vietnēm ar lielu satura apjomu tas var palielināt izmaksas un reālajiem apmeklētājiem sagādāt sliktu pieredzi. Lai taupītu resursus, varat izmantot Robots.txt, lai bloķētu piekļuvi skriptiem, mazsvarīgiem attēliem u. c.
- Svarīgu lapu prioritāšu noteikšana - Vēlaties, lai meklētājprogrammu zirnekļi pārmeklētu svarīgās vietnes lapas (piemēram, satura lapas), nevis tērētu resursus, lai šķirstītu bezjēdzīgas lapas (piemēram, meklēšanas vaicājumu rezultātus). Bloķējot šādas bezjēdzīgas lapas, varat noteikt prioritātes, kurām lapām roboti pievērš uzmanību.
Kā atrast Robots.txt failu
Kā liecina nosaukums, Robots.txt ir vienkāršs teksta fails.
Šis fails tiek glabāts jūsu vietnes saknes direktorijā. Lai to atrastu, vienkārši atveriet FTP rīku un dodieties uz savas vietnes direktoriju sadaļā public_html.

Šis ir neliels teksta fails - mans ir nedaudz vairāk par 100 baitiem.
Lai to atvērtu, izmantojiet jebkuru teksta redaktoru, piemēram, Notepad. Var parādīties kaut kas līdzīgs šim:

Pastāv iespēja, ka vietnes saknes direktorijā neredzēsiet nevienu Robots.txt failu. Šādā gadījumā Robots.txt fails būs jāizveido pašam.
Lūk, kā:
Kā izveidot failu Robot.txt
Tā kā robots.txt ir vienkāršs teksta fails, tā izveide ir ļoti vienkārša - vienkārši atveriet teksta redaktoru un saglabājiet tukšu failu kā robots.txt.

Lai augšupielādētu šo failu uz serveri, izmantojiet savu iecienītāko FTP rīku (iesaku izmantot WinSCP), lai pieteiktos savā tīmekļa serverī. Pēc tam atveriet mapi public_html un atveriet vietnes saknes direktoriju.
Atkarībā no tā, kā konfigurēts jūsu tīmekļa resursdators, jūsu vietnes saknes direktorija var atrasties tieši mapē public_html vai arī tā var būt kāda tās mape.
Kad esat atvēris vietnes saknes direktoriju, vienkārši velciet un iemetiet tajā Robots.txt failu.

Robots.txt failu varat izveidot arī tieši no FTP redaktora.
Lai to izdarītu, atveriet vietnes saknes direktoriju un ar peles labo pogu noklikšķiniet -> Izveidot jaunu failu.
Dialoglodziņā ierakstiet "robots.txt" (bez pēdiņām) un nospiediet OK.

Jums vajadzētu redzēt jaunu robots.txt failu:

Visbeidzot, pārliecinieties, ka esat iestatījis pareizo faila atļauju Robots.txt failam. Jūs vēlaties, lai īpašnieks - jūs pats - varētu lasīt un rakstīt failu, bet ne citi vai publiski.
Robots.txt failā kā atļaujas kodam jābūt "0644".
Ja tā nav, noklikšķiniet uz Robots.txt faila ar peles labo pogu un izvēlieties "Failu atļaujas...".

Lūk, tas ir - pilnībā funkcionējošs Robots.txt fails!
Bet ko jūs faktiski varat darīt ar šo failu?
Tālāk es jums parādīšu dažus kopīgus norādījumus, ko varat izmantot, lai kontrolētu piekļuvi vietnei.
Kā lietot Robots.txt
Atcerieties, ka Robots.txt būtībā kontrolē robotu mijiedarbību ar jūsu vietni.
Ja vēlaties bloķēt meklētājprogrammām piekļuvi visai vietnei? Vienkārši mainiet atļaujas Robots.txt.
Vai vēlaties bloķēt Bing saziņas lapas indeksēšanu? Arī to varat izdarīt.
Skatīt arī: Kā iegūt vairāk Instagram sekotāju 2023. gadā: galīgais ceļvedisRobots.txt fails pats par sevi neuzlabos jūsu SEO, taču varat to izmantot, lai kontrolētu rāpuļu darbību vietnē.
Lai pievienotu vai mainītu failu, vienkārši atveriet to savā FTP redaktorā un pievienojiet tekstu tieši. Kad saglabāsiet failu, izmaiņas tiks atspoguļotas nekavējoties.
Šeit ir dažas komandas, ko varat izmantot Robots.txt failā:
1. Bloķējiet visus botus savā vietnē
Vai vēlaties bloķēt visus robotus, kas pārmeklē jūsu vietni?
Pievienojiet šo kodu savam Robots.txt failam:
Lietotāja aģents: *Aizliegt: /
Šādi tas izskatās faktiskajā failā:

Vienkāršāk sakot, šī komanda katram lietotāja aģentam (*) aizliedz piekļūt jebkuriem failiem vai mapēm jūsu vietnē.
Šeit ir sniegts pilnīgs skaidrojums par to, kas tieši šeit notiek:
- Lietotāja aģents:* - Zvaigznīte (*) ir "aizstājējzīme", kas attiecas uz katru objektu (piemēram, faila nosaukumu vai šajā gadījumā - bot). Ja datorā meklēsiet "*.txt", tiks parādīti visi faili ar paplašinājumu .txt. Šajā gadījumā zvaigznīte nozīmē, ka jūsu komanda attiecas uz. katru lietotāja aģents.
- Aizliegt: / - "Disallow" ir robots.txt komanda, kas aizliedz botam pārmeklēt mapi. Viena slīpsvītra uz priekšu (/) nozīmē, ka šī komanda tiek piemērota saknes direktorijai.
Piezīme: Tas ir ideāli piemērots, ja pārvaldāt kādu privātu vietni, piemēram, dalības vietni. Taču ņemiet vērā, ka tas neļaus visiem likumīgajiem robotiem, piemēram, Google, pārmeklēt jūsu vietni. Izmantojiet piesardzīgi.
2. Bloķēt visu robotu piekļuvi konkrētai mapei
Ko darīt, ja vēlaties novērst, ka roboti pārmeklē un indeksē konkrētu mapi?
Piemēram, mape /images?
Izmantojiet šo komandu:
Skatīt arī: 16 Labākie mākslīgā intelekta rakstīšanas programmatūras rīki 2023. gadam (plusi un mīnusi)Lietotāja aģents: *Aizliegt: /[mapes_nosaukums]/
Ja vēlaties apturēt botus no piekļuves mapei /images, šeit ir redzams, kā izskatās šī komanda:

Šī komanda ir noderīga, ja jums ir resursu mape, kuru nevēlaties pārslogot ar robotu rāpuļu pieprasījumiem. Tā var būt mape ar mazsvarīgiem skriptiem, novecojušiem attēliem utt.
Piezīme: Aile /images ir tikai piemērs. Es nesaku, ka jums vajadzētu bloķēt robotu pārlūkošanu šajā mapē. Tas ir atkarīgs no tā, ko jūs mēģināt panākt.
Meklētājprogrammas parasti nelabvēlīgi izturas pret tīmekļa vietņu administratoriem, kas bloķē savus robotus, lai tie pārmeklētu mapes, kas nav attēlu mapes, tāpēc, izmantojot šo komandu, esiet piesardzīgi. Tālāk uzskaitītas dažas Robots.txt alternatīvas, lai aizkavētu meklētājprogrammām indeksēt noteiktas lapas.
3. Bloķējiet konkrētus botus savā vietnē
Ko darīt, ja vēlaties bloķēt konkrētu robotu, piemēram, Googlebot, piekļuvi jūsu vietnei?
Lūk, tā komanda:
Lietotāja aģents: [robota nosaukums]Aizliegt: /
Piemēram, ja vēlaties bloķēt Googlebot piekļuvi vietnei, izmantojiet šo saiti:

Katram likumīgajam robotam vai lietotāja aģentam ir īpašs nosaukums. Piemēram, Google zirnekli sauc vienkārši par "Googlebot". Microsoft izmanto gan "msnbot", gan "bingbot". Yahoo robotu sauc par "Yahoo! Slurp".
Lai uzzinātu precīzus dažādu lietotāju aģentu (piemēram, Googlebot, bingbot u. c.) nosaukumus, izmantojiet šo lapu.
Piezīme: Iepriekš minētā komanda bloķētu konkrētu robotu no visas vietnes. Googlebot ir izmantots tikai kā piemērs. Vairumā gadījumu jūs nekad nevēlaties apturēt Google pārlūkošanu jūsu vietnē. Viens īpašs konkrēto robotu bloķēšanas izmantošanas gadījums ir saglabāt tos robotus, kas sniedz jums labumu, lai apmeklētu jūsu vietni, un apturēt tos, kas nedod labumu jūsu vietnei.
4. Bloķēt konkrētu failu no pārlūkošanas
Robotu izslēgšanas protokols ļauj precīzi kontrolēt, kuriem failiem un mapēm vēlaties bloķēt robotu piekļuvi.
Šeit ir komanda, ko varat izmantot, lai apturētu faila pārlūkošanu ar jebkuru robotu:
Lietotāja aģents: *Aizliegt: /[mapes_nosaukums]/[faila_nosaukums.paplašinājums]
Tātad, ja vēlaties bloķēt failu ar nosaukumu "img_0001.png" no mapes "images", jāizmanto šī komanda:

5. Bloķēt piekļuvi mapei, bet ļaut indeksēt failu.
Komanda "Aizliegt" bloķē botiem piekļuvi mapei vai datnei.
Komanda "Atļaut" dara pretējo.
Komanda "Atļaut" aizstāj komandu "Aizliegt", ja pirmā ir vērsta uz atsevišķu failu.
Tas nozīmē, ka varat bloķēt piekļuvi mapei, bet lietotāja aģentiem joprojām ļaut piekļūt atsevišķiem mapes failiem.
Šeit ir norādīts, kāds formāts jāizmanto:
Lietotāja aģents: *Aizliegt: /[mapes_nosaukums]/
Atļaut: /[mapes_nosaukums]/[faila_nosaukums.paplašinājums]/
Piemēram, ja vēlaties bloķēt Google pārlūkošanu mapē "images", bet tomēr vēlaties tai nodrošināt piekļuvi tajā saglabātajam failam "img_0001.png", izmantojiet šādu formātu:
Iepriekš minētajā piemērā tas izskatās šādi:

Tādējādi visas /search/ direktorijā esošās lapas netiks indeksētas.
Ko darīt, ja vēlaties, lai netiktu indeksētas visas lapas, kas atbilst noteiktam paplašinājumam (piemēram, ".php" vai ".png")?
Izmantojiet šo:
Lietotāja aģents: *Aizliegt: /*.extension$
Šeit zīme ($) apzīmē URL adresāta beigas, t. i., paplašinājums ir pēdējā virkne URL adresē.
Ja vēlaties bloķēt visas lapas ar paplašinājumu ".js" (kas apzīmē Javascript), izmantojiet šo saiti:

Šī komanda ir īpaši efektīva, ja vēlaties apturēt robotu pārmeklēšanu skriptos.
6. Pārtrauciet botiem pārāk bieži pārmeklēt jūsu vietni.
Iepriekš minētajos piemēros, iespējams, redzējāt šo komandu:
Lietotāja aģents: *Ložņu aizkavēšanās: 20
Šī komanda uzdod visiem robotiem gaidīt vismaz 20 sekundes starp pārlūkošanas pieprasījumiem.
Komandu Crawl-Delay bieži izmanto lielās vietnēs ar bieži atjauninātu saturu (piemēram, Twitter). Šī komanda norāda robotiem gaidīt minimālu laiku starp nākamajiem pieprasījumiem.
Tas nodrošina, ka serveris netiek pārslogots ar pārāk daudziem pieprasījumiem no dažādiem robotiem vienlaicīgi.
Piemēram, šis ir Twitter Robots.txt fails, kurā norādīts, ka robotiem starp pieprasījumiem jāgaida vismaz 1 sekundi:

Varat pat kontrolēt atsevišķu robotu pārlūkošanas aizkavi. Tas nodrošina, ka pārāk daudz robotu vienlaicīgi nepārlūko jūsu vietni.
Piemēram, var būt šāds komandu kopums:

Piezīme: Šī komanda jums nebūs jāizmanto, ja vien nelietojat milzīgu vietni ar tūkstošiem jaunu lapu, kas tiek izveidotas katru minūti (piemēram, Twitter).
Biežāk pieļautās kļūdas, no kurām jāizvairās, izmantojot Robots.txt
Robots.txt fails ir spēcīgs rīks, lai kontrolētu robotu darbību jūsu vietnē.
Tomēr, ja to neizmanto pareizi, tas var arī novest pie SEO katastrofas. Tas nepalīdz, jo internetā valda vairāki maldīgi priekšstati par Robots.txt.
Šeit ir dažas kļūdas, no kurām jāizvairās, izmantojot Robots.txt:
Kļūda Nr. 1 - Robots.txt izmantošana, lai novērstu satura indeksēšanu
Ja Robots.txt failā "Aizliegsiet" mapi, likumīgi roboti to neapmeklēs.
Taču tas joprojām nozīmē divas lietas:
- Boti pārmeklēs mapes saturu, uz kuru ir saites no ārējiem avotiem. Teiksim, ja cita vietne sasaista jūsu bloķētajā mapē esošo failu, roboti to indeksēs.
- Ļaunprātīgi roboti - surogātpasta sūtītāji, spiegprogrammatūra, ļaunprātīga programmatūra u. c. - parasti ignorēs Robots.txt norādījumus un indeksēs jūsu saturu neatkarīgi no tiem.
Tāpēc Robots.txt ir slikts rīks, lai novērstu satura indeksēšanu.
Tā vietā jāizmanto birka "meta noindex".
Lapās, kuras nevēlaties indeksēt, pievienojiet šādu tagu:
Šī ir ieteicamā, SEO draudzīgā metode, lai apturētu lapas indeksēšanu (lai gan tā joprojām nebloķē surogātpasta sūtītājus).
Piezīme: Ja izmantojat WordPress spraudni, piemēram, Yoast SEO vai All in One SEO; to varat izdarīt, nerediģējot kodu. Piemēram, Yoast SEO spraudnī var pievienot noindex tagu katram postam/lapai, piemēram, šādi:

Vienkārši atveriet ziņu/lapu un noklikšķiniet uz Yoast SEO lodziņa iekšpusē esošā zobrata. Pēc tam noklikšķiniet uz nolaižamajā logā blakus "Meta robots indekss".
Turklāt no 1. septembra Google vairs neatbalstīs "noindex" izmantošanu robots.txt failos. Vairāk informācijas ir sniegts šajā SearchEngineLand rakstā.
Kļūda Nr. 2 - Robots.txt izmantošana privātā satura aizsardzībai
Ja jums ir privāts saturs, piemēram, e-pasta kursu PDF formātā, direktorija bloķēšana, izmantojot Robots.txt failu, palīdzēs, taču ar to nepietiek.
Lūk, kāpēc:
Saturs joprojām var tikt indeksēts, ja uz to ir saites no ārējiem avotiem. Turklāt negodīgi roboti joprojām to pārlūko.
Labāka metode ir saglabāt visu privāto saturu aiz pieteikumvārda. Tas nodrošinās, ka neviens - ne likumīgi, ne negodīgi roboti - nevarēs piekļūt jūsu saturam.
Negatīvā puse ir tā, ka tas nozīmē, ka jūsu apmeklētājiem būs jāpārvar papildu šķēršļi. Taču jūsu saturs būs drošāks.
Kļūda #3 - Robots.txt izmantošana, lai apturētu satura dublēšanos indeksēšanā
Divkāršs saturs ir liels "nē", kad runa ir par SEO.
Tomēr Robots.txt izmantošana, lai apturētu šī satura indeksēšanu, nav risinājums. Arī šajā gadījumā nav garantijas, ka meklētājprogrammu zirnekļi neatradīs šo saturu, izmantojot ārējos avotus.
Šeit ir vēl 3 veidi, kā apstrādāt dublējošu saturu:
- Dzēst dublējošu saturu - Tas pilnībā atbrīvosies no satura. Tomēr tas nozīmē, ka jūs novedīsiet meklētājprogrammas uz 404. lapu - tas nav ideāli. Tādēļ, dzēšana nav ieteicama. .
- Izmantojiet 301 novirzīšanu - 301 novirzīšana norāda meklētājprogrammām (un apmeklētājiem), ka lapa ir pārvietota uz jaunu atrašanās vietu. Vienkārši pievienojiet 301 novirzīšanu dublējošam saturam, lai novirzītu apmeklētājus uz jūsu sākotnējo saturu.
- Pievienot rel="canonical" tagu - Šī ir 301 pāradresēšanas "meta" versija. Tags "rel=canonical" norāda Google, kurš ir konkrētās lapas sākotnējais URL. Piemēram, šis kods:
//example.com/original-page.html " rel="canonical" />
Paziņo Google, ka lapa - original-page.html - ir dublētās lapas "oriģinālā" versija. Ja izmantojat WordPress, šo tagu ir viegli pievienot, izmantojot Yoast SEO vai All in One SEO.
Ja vēlaties, lai apmeklētāji varētu piekļūt dublētajam saturam, izmantojiet rel="canonical" tagu. Ja nevēlaties, lai apmeklētāji vai roboti piekļūtu saturam, izmantojiet 301 pāradresāciju.
Uzmanīgi ievietojiet abus šos rīkus, jo tie ietekmēs jūsu SEO.
Jūsu pārziņā
Robots.txt fails ir noderīgs sabiedrotais, lai noteiktu veidu, kā meklētājprogrammu zirnekļi un citi roboti mijiedarbojas ar jūsu vietni. Pareizi izmantots, tas var pozitīvi ietekmēt jūsu vietnes klasifikāciju un atvieglot tās pārlūkošanu.
Izmantojiet šo ceļvedi, lai saprastu, kā darbojas Robots.txt, kā tas tiek instalēts, un dažus izplatītākos veidus, kā to izmantot. Un izvairieties no iepriekš minētajām kļūdām.
Saistītā lasīšana:
- Labākie ranga izsekošanas rīki blogeriem, salīdzinājums
- Galīgais ceļvedis Google saišu iegūšanai
- 5 jaudīgu atslēgvārdu izpētes rīku salīdzinājums
