Co je soubor Robots.txt a jak ho vytvořit? (Průvodce pro začátečníky)

Obsah
Věděli jste, že máte plnou kontrolu nad tím, kdo váš web prohledává a indexuje, a to až do úrovně jednotlivých stránek?
K tomu slouží soubor Robots.txt.
Robots.txt je jednoduchý textový soubor, který se nachází v kořenovém adresáři vašeho webu. Říká robotům (například pavoukům vyhledávačů), které stránky mají na vašem webu procházet a které ignorovat.
Soubor Robots.txt sice není nezbytný, ale poskytuje vám velkou kontrolu nad tím, jak Google a další vyhledávače vidí vaše stránky.
Při správném použití může zlepšit procházení a dokonce ovlivnit SEO.
Jak ale přesně vytvořit efektivní soubor Robots.txt? Jak ho používat, když už je vytvořen? A jakých chyb byste se měli při jeho používání vyvarovat?
V tomto příspěvku se s vámi podělím o vše, co potřebujete vědět o souboru Robots.txt a o tom, jak jej používat na svém blogu.
Pojďme se do toho ponořit:
Co je soubor Robots.txt?
V počátcích internetu vytvořili programátoři a inženýři "roboty" nebo "pavouky", kteří procházeli a indexovali stránky na webu. Tito roboti jsou také známí jako "uživatelští agenti".
Někdy se tito roboti dostanou na stránky, které majitelé stránek nechtěli indexovat. Například na stránky ve výstavbě nebo na soukromé webové stránky.
Aby tento problém vyřešil, navrhl Martijn Koster, nizozemský inženýr, který vytvořil první vyhledávač na světě (Aliweb), soubor standardů, které by musel dodržovat každý robot. Tyto standardy byly poprvé navrženy v únoru 1994.
Dne 30. června 1994 se řada autorů robotů a prvních průkopníků webu shodla na standardech.
Tyto normy byly přijaty jako "Protokol o vyloučení robotů" (REP).
Soubor Robots.txt je implementací tohoto protokolu.
REP definuje soubor pravidel, kterými se musí řídit každý legitimní crawler nebo pavouk. Pokud soubor Robots.txt nařizuje robotům neindexovat webovou stránku, každý legitimní robot - od Googlebot po MSNbot - se musí těmito pokyny řídit.
Poznámka: Seznam legitimních crawlerů naleznete zde.
Mějte na paměti, že někteří podvodní roboti - malware, spyware, e-mail harvestery atd. - nemusí tyto protokoly dodržovat. Proto se může stát, že se na stránkách, které jste zablokovali pomocí souboru Robots.txt, objeví provoz botů.
Existují také roboti, kteří nedodržují standardy REP a nejsou používáni k ničemu pochybnému.
Soubor robots.txt jakékoli webové stránky si můžete prohlédnout na této adrese:
//[doména_webu]/robots.txt
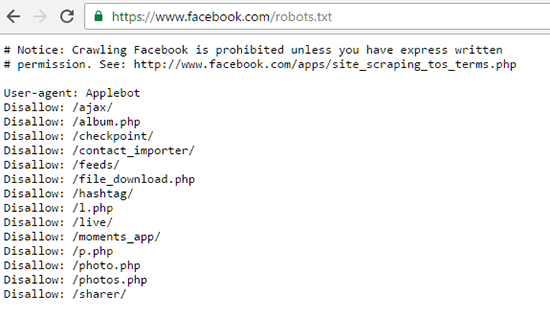
Zde je například soubor Robots.txt společnosti Facebook:
A zde je soubor Robots.txt společnosti Google:

Použití souboru Robots.txt
Soubor Robots.txt není pro webové stránky nezbytný. Vaše stránky se mohou bez tohoto souboru dobře umisťovat a růst.
Použití souboru Robots.txt však přináší některé výhody:
- Odradit roboty od procházení soukromých složek - Ačkoli to není dokonalé, znemožnění procházení soukromých složek robotům výrazně ztíží jejich indexaci - alespoň legitimním robotům (například pavoukům vyhledávačů).
- Řízení využívání zdrojů - Pokaždé, když bot prochází vaše stránky, vyčerpává šířku pásma a zdroje serveru - zdroje, které by bylo lepší využít pro skutečné návštěvníky. U stránek s velkým množstvím obsahu to může zvýšit náklady a skutečným návštěvníkům poskytnout špatný zážitek. Pomocí souboru Robots.txt můžete zablokovat přístup ke skriptům, nedůležitým obrázkům atd., abyste ušetřili zdroje.
- Stanovte si priority důležitých stránek - Chcete, aby pavouci vyhledávačů procházeli důležité stránky vašeho webu (např. stránky s obsahem) a neplýtvali zdroji na prohledávání zbytečných stránek (např. výsledků vyhledávacích dotazů). Zablokováním těchto zbytečných stránek můžete určit priority, na které stránky se roboti zaměří.
Jak najít soubor Robots.txt
Jak název napovídá, Robots.txt je jednoduchý textový soubor.
Tento soubor je uložen v kořenovém adresáři vašich webových stránek. Chcete-li jej najít, otevřete nástroj FTP a přejděte do adresáře svých webových stránek v části public_html.

Jedná se o malý textový soubor - můj má něco málo přes 100 bajtů.
Chcete-li jej otevřít, použijte libovolný textový editor, například Poznámkový blok. Zobrazí se něco podobného:

Je možné, že v kořenovém adresáři webu neuvidíte žádný soubor Robots.txt. V takovém případě budete muset soubor Robots.txt vytvořit sami.
Zde je návod, jak na to:
Jak vytvořit soubor Robot.txt
Protože Robots.txt je základní textový soubor, je jeho vytvoření velmi jednoduché - stačí otevřít textový editor a uložit prázdný soubor jako robots.txt.

Chcete-li tento soubor nahrát na server, přihlaste se pomocí svého oblíbeného nástroje FTP (doporučuji použít WinSCP) k webovému serveru. Poté otevřete složku public_html a kořenový adresář webu.
V závislosti na tom, jak je váš webový hostitel nakonfigurován, může být kořenový adresář vašeho webu přímo ve složce public_html. Nebo to může být složka uvnitř této složky.
Jakmile máte otevřený kořenový adresář webu, přetáhněte do něj soubor Robots.txt.

Soubor Robots.txt můžete také vytvořit přímo v editoru FTP.
Chcete-li to provést, otevřete kořenový adresář webu a klikněte pravým tlačítkem myši -> Vytvořit nový soubor.
Do dialogového okna zadejte "robots.txt" (bez uvozovek) a stiskněte tlačítko OK.

V něm by se měl zobrazit nový soubor robots.txt:

Nakonec se ujistěte, že jste pro soubor Robots.txt nastavili správná oprávnění. Chcete, aby soubor mohl číst a zapisovat jeho vlastník - vy sami -, ale ne ostatní nebo veřejnost.
Viz_také: Jak používat pomlčky ve WordPressu - průvodce krok za krokemV souboru Robots.txt by měl být jako kód oprávnění uveden "0644".
Pokud se tak nestane, klikněte pravým tlačítkem myši na soubor Robots.txt a vyberte možnost "Oprávnění k souboru...".

A je to - plně funkční soubor Robots.txt!
Co ale můžete s tímto souborem vlastně dělat?
Dále vám ukážu několik běžných pokynů, které můžete použít k řízení přístupu na váš web.
Jak používat soubor Robots.txt
Nezapomeňte, že soubor Robots.txt v podstatě řídí interakci robotů s vaším webem.
Chcete vyhledávačům zablokovat přístup k celému webu? Stačí změnit oprávnění v souboru Robots.txt.
Chcete zablokovat indexování kontaktní stránky službou Bing? I to můžete udělat.
Soubor Robots.txt sám o sobě nezlepší vaši SEO optimalizaci, ale můžete jej použít ke kontrole chování crawlerů na vašem webu.
Chcete-li soubor přidat nebo upravit, jednoduše jej otevřete v editoru FTP a přímo do něj přidejte text. Jakmile soubor uložíte, změny se okamžitě projeví.
Zde je několik příkazů, které můžete použít v souboru Robots.txt:
1. Zablokujte všechny roboty na svých stránkách
Chcete zablokovat procházení webu všemi roboty?
Přidejte tento kód do souboru Robots.txt:
User-agent: *Zakázat: /
Takto by to vypadalo ve skutečném souboru:

Zjednodušeně řečeno, tento příkaz říká všem uživatelským agentům (*), aby nepřistupovali k žádným souborům nebo složkám na vašem webu.
Zde je kompletní vysvětlení, co se zde přesně děje:
- Agent uživatele:* - Hvězdička (*) je znak "divoké karty", který se vztahuje na každý (jako je název souboru nebo v tomto případě bot). Pokud v počítači vyhledáte "*.txt", zobrazí se všechny soubory s příponou .txt. Hvězdička zde znamená, že se váš příkaz vztahuje na soubory s příponou .txt. každý user-agent.
- Zakázat: / - "Disallow" je příkaz robots.txt, který zakazuje robotovi procházet složku. Jedno lomítko vpřed (/) znamená, že tento příkaz použijete na kořenový adresář.
Poznámka: To je ideální, pokud provozujete jakýkoli druh soukromých webových stránek, například členské stránky. Uvědomte si však, že to zabrání všem legitimním robotům, jako je Google, v procházení vašich stránek. Používejte s opatrností.
2. Zablokování přístupu všech botů do určité složky
Co když chcete robotům zabránit v procházení a indexování určité složky?
Například složka /images?
Použijte tento příkaz:
User-agent: *Zakázat: /[název_složky]/
Pokud byste chtěli zabránit botům v přístupu do složky /images, příkaz by vypadal takto:

Tento příkaz je užitečný, pokud máte složku se zdroji, kterou nechcete zahltit požadavky robotů crawlerů. Může to být složka s nedůležitými skripty, zastaralými obrázky atd.
Poznámka: Složka /images je čistě příklad. Neříkám, že byste měli blokovat procházení této složky roboty. Záleží na tom, čeho se snažíte dosáhnout.
Vyhledávače obvykle nesouhlasí s tím, aby jejich roboti blokovali procházení jiných složek než složek s obrázky, proto buďte při používání tohoto příkazu opatrní. Níže uvádím několik alternativ k souboru Robots.txt, které brání vyhledávačům v indexování konkrétních stránek.
3. Zablokování konkrétních robotů na vašich stránkách
Co když chcete zablokovat přístup určitého robota - například Googlebot - na své stránky?
Zde je jeho příkaz:
User-agent: [jméno robota]Zakázat: /
Pokud byste například chtěli zablokovat přístup Googlebota na své stránky, použili byste tento příkaz:

Každý legitimní bot nebo uživatelský agent má specifický název. Například pavouk společnosti Google se nazývá jednoduše "Googlebot". Microsoft provozuje jak "msnbot", tak "bingbot". Bot společnosti Yahoo se nazývá "Yahoo! Slurp".
Přesné názvy různých uživatelských agentů (např. Googlebot, bingbot atd.) najdete na této stránce.
Poznámka: Výše uvedený příkaz zablokuje konkrétního bota na celém vašem webu. Googlebot je použit pouze jako příklad. Ve většině případů byste nikdy nechtěli zabránit Googlu v procházení vašeho webu. Jedním z konkrétních případů použití blokování konkrétních botů je udržet roboty, kteří vám přinášejí užitek, na vašem webu, a zároveň zastavit ty, kteří vašemu webu užitek nepřinášejí.
4. Zablokování procházení určitého souboru
Protokol o vyloučení robotů umožňuje jemnou kontrolu nad tím, ke kterým souborům a složkám chcete zablokovat přístup robotů.
Zde je příkaz, který můžete použít k zastavení procházení souboru jakýmkoli robotem:
User-agent: *Zakázat: /[název_složky]/[název_souboru.přípona]
Pokud tedy chcete zablokovat soubor s názvem "img_0001.png" ze složky "images", použijete tento příkaz:

5. Zablokování přístupu ke složce, ale povolení indexování souboru
Příkaz "Zakázat" blokuje botům přístup ke složce nebo souboru.
Příkaz "Povolit" dělá pravý opak.
Příkaz "Povolit" nahrazuje příkaz "Zakázat", pokud je první z nich zaměřen na jednotlivý soubor.
To znamená, že můžete zablokovat přístup ke složce, ale přesto umožnit uživatelským agentům přístup k jednotlivým souborům v této složce.
Zde je uveden formát, který je třeba použít:
User-agent: *Zakázat: /[název_složky]/
Povolit: /[název_složky]/[název_souboru.přípona]/
Pokud byste například chtěli zablokovat procházení složky "images" společností Google, ale přesto byste jí chtěli umožnit přístup k souboru "img_0001.png", který je v ní uložen, použijte tento formát:
Pro výše uvedený příklad by to vypadalo takto:

Tím by se zastavilo indexování všech stránek v adresáři /search/.
Co když chcete zabránit indexování všech stránek, které odpovídají určité příponě (například ".php" nebo ".png")?
Použijte tento postup:
User-agent: *Zakázat: /*.extension$
Znak ($) zde označuje konec adresy URL, tj. přípona je posledním řetězcem v adrese URL.
Pokud byste chtěli zablokovat všechny stránky s příponou ".js" (pro Javascript), použili byste tento příkaz:
Viz_také: 11 dalších zdrojů příjmů pro webové vývojáře a designéry
Tento příkaz je obzvláště účinný, pokud chcete zabránit robotům v procházení skriptů.
6. Zabraňte robotům v příliš častém procházení vašich stránek
Ve výše uvedených příkladech jste se mohli setkat s tímto příkazem:
User-agent: *Zpoždění při plazení: 20
Tento příkaz nařídí všem botům, aby mezi jednotlivými požadavky na procházení čekali minimálně 20 sekund.
Příkaz Crawl-Delay se často používá na velkých webech s často aktualizovaným obsahem (například Twitter). Tento příkaz říká robotům, aby mezi jednotlivými požadavky počkali určitou minimální dobu.
Tím se zajistí, že server nebude zahlcen příliš mnoha požadavky od různých botů najednou.
Jedná se například o soubor Robots.txt společnosti Twitter, který robotům nařizuje, aby mezi jednotlivými požadavky počkali minimálně 1 sekundu:

Můžete dokonce ovládat zpoždění procházení pro jednotlivé roboty. Tím zajistíte, že váš web nebude procházet příliš mnoho robotů najednou.
Můžete mít například tuto sadu příkazů:

Poznámka: Tento příkaz nebudete potřebovat, pokud neprovozujete rozsáhlý web s tisíci nově vytvořenými stránkami každou minutu (jako Twitter).
Časté chyby, kterých se při používání souboru Robots.txt vyvarujte
Soubor Robots.txt je mocným nástrojem pro kontrolu chování botů na vašem webu.
Pokud se však nepoužívá správně, může vést ke katastrofě SEO. Nepomáhá ani to, že na internetu koluje řada mylných představ o souboru Robots.txt.
Zde je několik chyb, kterých se musíte při používání souboru Robots.txt vyvarovat:
Chyba č. 1 - Použití souboru Robots.txt k zabránění indexování obsahu
Pokud složku v souboru Robots.txt zakážete, legitimní roboti ji nebudou procházet.
To však stále znamená dvě věci:
- Boti budou procházet obsah složky, na kterou vedou odkazy z externích zdrojů. Řekněme, že pokud jiný web odkazuje na soubor ve vaší blokované složce, roboti jej budou sledovat a indexovat.
- Podvodní roboti - spammeři, spyware, malware atd. - obvykle ignorují pokyny souboru Robots.txt a indexují váš obsah bez ohledu na ně.
Proto je soubor Robots.txt špatným nástrojem, jak zabránit indexování obsahu.
Místo toho byste měli použít tento postup: použijte značku 'meta noindex'.
Na stránky, které nechcete indexovat, přidejte následující značku:
Jedná se o doporučenou metodu, která je šetrná k SEO a zabraňuje indexování stránky (i když stále neblokuje spammery).
Poznámka: Pokud používáte plugin WordPress, jako je Yoast SEO nebo All in One SEO, můžete to udělat bez úpravy kódu. Například v pluginu Yoast SEO můžete přidat značku noindex na základě jednotlivých příspěvků/stránek takto:

Stačí otevřít příspěvek/stránku a kliknout na ozubené kolečko uvnitř pole Yoast SEO. Poté klikněte na rozevírací seznam vedle položky "Meta robots index".
Kromě toho Google od 1. září přestane podporovat používání "noindex" v souborech robots.txt. Více informací naleznete v tomto článku z webu SearchEngineLand.
Chyba č. 2 - Používání souboru Robots.txt k ochraně soukromého obsahu
Pokud máte soukromý obsah - například soubory PDF pro e-mailový kurz - blokování adresáře pomocí souboru Robots.txt pomůže, ale nestačí.
Zde je důvod:
Váš obsah může být indexován i v případě, že na něj vedou odkazy z externích zdrojů. Navíc jej budou procházet nepoctiví roboti.
Lepší metodou je uchovávat veškerý soukromý obsah za přihlašovacím jménem. Tím zajistíte, že se k vašemu obsahu nedostane nikdo - legitimní ani nepoctiví roboti.
Nevýhodou je, že návštěvníci musí překonávat další překážku. Váš obsah však bude bezpečnější.
Chyba č. 3 - Použití souboru Robots.txt k zabránění indexování duplicitního obsahu
Duplicitní obsah je z hlediska SEO velmi nepřípustný.
Použití souboru Robots.txt k zabránění indexování tohoto obsahu však není řešením. Opět není zaručeno, že pavouci vyhledávačů tento obsah nenajdou prostřednictvím externích zdrojů.
Zde jsou další 3 způsoby, jak zpracovat duplicitní obsah:
- Odstranění duplicitního obsahu - Tím se obsahu zbavíte úplně. To však znamená, že vyhledávače zavedete na stránky 404 - což není ideální. Z tohoto důvodu, odstranění se nedoporučuje .
- Použijte přesměrování 301 - Přesměrování 301 informuje vyhledávače (a návštěvníky), že se stránka přesunula na nové místo. Stačí přidat přesměrování 301 na duplicitní obsah, aby se návštěvníci dostali na původní obsah.
- Přidání značky rel="canonical" - Tato značka je meta verzí přesměrování 301. Značka "rel=canonical" říká společnosti Google, která je původní adresa URL pro konkrétní stránku. Například tento kód:
//example.com/original-page.html " rel="canonical" />
Říká Googlu, že stránka - original-page.html - je "původní" verze duplicitní stránky. Pokud používáte WordPress, tento tag snadno přidáte pomocí Yoast SEO nebo All in One SEO.
Pokud chcete, aby návštěvníci měli přístup k duplicitnímu obsahu, použijte příkaz rel="canonical" tag. Pokud nechcete, aby návštěvníci nebo roboti měli přístup k obsahu - použijte přesměrování 301.
Buďte opatrní při implementaci obou, protože budou mít vliv na vaši SEO.
Přepínám na vás
Soubor Robots.txt je užitečným spojencem při určování způsobu, jakým pavouci vyhledávačů a další roboti pracují s vaším webem. Při správném použití může mít pozitivní vliv na vaše hodnocení a usnadnit procházení vašeho webu.
Pomocí tohoto průvodce pochopíte, jak Robots.txt funguje, jak se instaluje a jakými běžnými způsoby jej můžete používat. A vyvarujte se některé z chyb, které jsme probrali výše.
Související čtení:
- Nejlepší nástroje pro sledování pořadí pro blogery, porovnání
- Definitivní průvodce získáním odkazů na stránky Google
- Porovnání 5 výkonných nástrojů pro výzkum klíčových slov
