ໄຟລ໌ Robots.txt ແມ່ນຫຍັງ? ແລະເຈົ້າສ້າງອັນໃດແດ່? (ຄູ່ມືເລີ່ມຕົ້ນ)

ສາລະບານ
ທ່ານຮູ້ບໍ່ວ່າທ່ານມີການຄວບຄຸມຢ່າງສົມບູນກ່ຽວກັບຜູ້ທີ່ລວບລວມຂໍ້ມູນ ແລະດັດສະນີເວັບໄຊຂອງເຈົ້າ, ລົງໄປຫາແຕ່ລະໜ້າ? Robots.txt ເປັນໄຟລ໌ຂໍ້ຄວາມງ່າຍໆທີ່ຕັ້ງຢູ່ໃນລະບົບຮາກຂອງເວັບໄຊຂອງເຈົ້າ. ມັນບອກ "ຫຸ່ນຍົນ" (ເຊັ່ນ: spider ເຄື່ອງຈັກຊອກຫາ) ວ່າຫນ້າເວັບໃດທີ່ຈະລວບລວມຂໍ້ມູນຢູ່ໃນເວັບໄຊທ໌ຂອງທ່ານ, ຫນ້າໃດທີ່ຈະບໍ່ສົນໃຈ.
ເຖິງແມ່ນວ່າບໍ່ສໍາຄັນ, ໄຟລ໌ Robots.txt ເຮັດໃຫ້ທ່ານຄວບຄຸມຫຼາຍກ່ຽວກັບວິທີການ Google ແລະ ເຄື່ອງມືຄົ້ນຫາອື່ນໆເບິ່ງເວັບໄຊຂອງເຈົ້າ.
ເມື່ອໃຊ້ຢ່າງຖືກຕ້ອງ, ນີ້ສາມາດປັບປຸງການລວບລວມຂໍ້ມູນ ແລະແມ້ກະທັ້ງຜົນກະທົບຕໍ່ SEO.
ແຕ່ເຈົ້າສ້າງໄຟລ໌ Robots.txt ທີ່ມີປະສິດທິພາບໄດ້ແນວໃດ? ເມື່ອສ້າງແລ້ວ, ເຈົ້າໃຊ້ມັນແນວໃດ? ແລະເຈົ້າຄວນຫຼີກລ່ຽງຄວາມຜິດພາດອັນໃດໃນຂະນະທີ່ໃຊ້ມັນ?
ໃນໂພສນີ້, ຂ້ອຍຈະແບ່ງປັນທຸກຢ່າງທີ່ເຈົ້າຕ້ອງການຮູ້ກ່ຽວກັບໄຟລ໌ Robots.txt ແລະວິທີໃຊ້ມັນຢູ່ໃນບລັອກຂອງເຈົ້າ.
ມາເບິ່ງກັນເລີຍ:
ໄຟລ໌ Robots.txt ແມ່ນຫຍັງ?
ໃນຍຸກທຳອິດຂອງອິນເຕີເນັດ, ນັກຂຽນໂປຣແກຣມ ແລະວິສະວະກອນສ້າງ 'ຫຸ່ນຍົນ' ຫຼື 'ແມງມຸມ' ເພື່ອລວບລວມຂໍ້ມູນແລະດັດສະນີຫນ້າໃນເວັບ. ຫຸ່ນຍົນເຫຼົ່ານີ້ຍັງຖືກເອີ້ນວ່າ 'ຕົວແທນຜູ້ໃຊ້.'
ບາງເທື່ອ, ຫຸ່ນຍົນເຫຼົ່ານີ້ຈະນໍາທາງໄປສູ່ຫນ້າທີ່ເຈົ້າຂອງເວັບໄຊທ໌ບໍ່ຕ້ອງການທີ່ຈະໄດ້ຮັບການດັດສະນີ. ຕົວຢ່າງ, ເວັບໄຊທີ່ຢູ່ພາຍໃຕ້ການກໍ່ສ້າງ ຫຼືເວັບໄຊທ໌ສ່ວນຕົວ.
ເພື່ອແກ້ໄຂບັນຫານີ້, Martijn Koster, ວິສະວະກອນຊາວໂຮນລັງທີ່ສ້າງເຄື່ອງຈັກຊອກຫາທໍາອິດຂອງໂລກ (Aliweb), ໄດ້ສະເຫນີຊຸດມາດຕະຖານຂອງຫຸ່ນຍົນທຸກໂຕ.ໂຟນເດີທີ່ເຊື່ອມຕໍ່ຈາກແຫຼ່ງພາຍນອກ. ເວົ້າວ່າ, ຖ້າເວັບໄຊທ໌ອື່ນເຊື່ອມຕໍ່ກັບໄຟລ໌ພາຍໃນໂຟເດີທີ່ຖືກບລັອກຂອງທ່ານ, bots ຈະຕິດຕາມໂດຍດັດສະນີມັນ.
ນີ້ເຮັດໃຫ້ Robots.txt ເປັນເຄື່ອງມືທີ່ບໍ່ດີເພື່ອປ້ອງກັນບໍ່ໃຫ້ເນື້ອຫາຖືກດັດສະນີ.
ນີ້ແມ່ນສິ່ງທີ່ທ່ານຄວນໃຊ້ແທນ: ໃຊ້ແທັກ 'meta noindex'.
ເພີ່ມແທັກຕໍ່ໄປນີ້ໃນຫນ້າທີ່ເຈົ້າບໍ່ຕ້ອງການຖືກດັດສະນີ:
ນີ້ແມ່ນວິທີແນະນຳ SEO ທີ່ເປັນມິດກັບ SEO ເພື່ອຢຸດຫນ້າເວັບຈາກການຖືກດັດສະນີ (ເຖິງແມ່ນວ່າມັນຍັງບໍ່ຖືກບລັອກ. spammers).
ໝາຍເຫດ: ຖ້າທ່ານໃຊ້ plugin WordPress ເຊັ່ນ Yoast SEO, ຫຼື All in One SEO; ທ່ານສາມາດເຮັດສິ່ງນີ້ໄດ້ໂດຍບໍ່ຕ້ອງແກ້ໄຂລະຫັດໃດໆ. ຕົວຢ່າງ, ໃນ Yoast SEO plugin ທ່ານສາມາດເພີ່ມ tag noindex ບົນພື້ນຖານການຕອບ / ຫນ້າເຊັ່ນ:

ພຽງແຕ່ເປີດຂຶ້ນແລະໂພດ / ຫນ້າແລະຄລິກໃສ່ cog ພາຍໃນກ່ອງ Yoast SEO. . ຈາກນັ້ນຄລິກເມນູເລື່ອນລົງຖັດຈາກ 'Meta robots index.'
ນອກຈາກນັ້ນ, Google ຈະຢຸດການສະໜັບສະໜູນການນຳໃຊ້ "noindex" ໃນໄຟລ໌ robots.txt ຈາກວັນທີ 1 ກັນຍາ. ບົດຄວາມນີ້ຈາກ SearchEngineLand ມີຂໍ້ມູນເພີ່ມເຕີມ.
ຄວາມຜິດພາດ #2 – ການໃຊ້ Robots.txt ເພື່ອປົກປ້ອງເນື້ອຫາສ່ວນຕົວ
ຖ້າທ່ານມີເນື້ອຫາສ່ວນຕົວ – ໃຫ້ເວົ້າວ່າ, PDFs ສໍາລັບຫຼັກສູດອີເມລ໌ – ບລັອກໄດເລກະທໍລີຜ່ານ ໄຟລ໌ robots.txt ຈະຊ່ວຍໄດ້, ແຕ່ມັນບໍ່ພຽງພໍ.
ນີ້ແມ່ນເຫດຜົນ:
ເນື້ອຫາຂອງທ່ານອາດຈະຍັງໄດ້ຮັບການດັດສະນີຖ້າມັນຖືກເຊື່ອມຕໍ່ຈາກແຫຼ່ງພາຍນອກ. ນອກຈາກນັ້ນ, ບອທ໌ rogue ຍັງຈະລວບລວມມັນຢູ່.
ວິທີທີ່ດີກວ່າແມ່ນເພື່ອຮັກສາເນື້ອຫາສ່ວນຕົວທັງໝົດໄວ້ຫຼັງການເຂົ້າສູ່ລະບົບ. ນີ້ຈະຮັບປະກັນວ່າບໍ່ມີໃຜ - bots ທີ່ຖືກຕ້ອງຫຼື rogue - ຈະໄດ້ຮັບການເຂົ້າເຖິງເນື້ອຫາຂອງທ່ານ.
ຂໍ້ເສຍແມ່ນວ່າມັນຫມາຍຄວາມວ່າຜູ້ມາຢ້ຽມຢາມຂອງທ່ານມີ hoop ພິເສດທີ່ຈະຂ້າມຜ່ານ. ແຕ່, ເນື້ອຫາຂອງທ່ານຈະປອດໄພກວ່າ.
ຄວາມຜິດພາດ #3 – ການໃຊ້ Robots.txt ເພື່ອຢຸດເນື້ອຫາທີ່ຊ້ໍາກັນຈາກການຖືກດັດສະນີ
ເນື້ອຫາທີ່ຊ້ໍາກັນເປັນເລື່ອງທີ່ບໍ່ມີປະໂຫຍດໃນເວລາທີ່ມັນມາກັບ SEO.
ຢ່າງໃດກໍຕາມ, ການໃຊ້ Robots.txt ເພື່ອຢຸດເນື້ອຫານີ້ຈາກການຖືກດັດສະນີບໍ່ແມ່ນການແກ້ໄຂ. ອີກເທື່ອໜຶ່ງ, ບໍ່ມີການຮັບປະກັນວ່າ spider ເຄື່ອງຈັກຊອກຫາຈະບໍ່ຊອກຫາເນື້ອຫານີ້ຜ່ານແຫຼ່ງພາຍນອກ.
ນີ້ແມ່ນ 3 ວິທີອື່ນເພື່ອມອບເນື້ອຫາທີ່ຊ້ໍາກັນ:
- ລຶບ ເນື້ອຫາທີ່ຊ້ໍາກັນ - ນີ້ຈະກໍາຈັດເນື້ອຫາທັງຫມົດ. ຢ່າງໃດກໍຕາມ, ນີ້ຫມາຍຄວາມວ່າທ່ານກໍາລັງນໍາພາເຄື່ອງຈັກຊອກຫາ 404 ຫນ້າ - ບໍ່ເຫມາະສົມ. ດ້ວຍເຫດນີ້, ການລຶບບໍ່ຖືກແນະນຳໃຫ້ອອກ .
- ໃຊ້ 301 redirect – A 301 redirect in orders search engines (ແລະຜູ້ມາຢ້ຽມຢາມ) ວ່າຫນ້າເວັບໄດ້ຍ້າຍໄປບ່ອນໃຫມ່. . ພຽງແຕ່ເພີ່ມການປ່ຽນເສັ້ນທາງ 301 ໃນເນື້ອຫາທີ່ຊ້ໍາກັນເພື່ອນໍາຜູ້ເຂົ້າຊົມໄປຫາເນື້ອຫາຕົ້ນສະບັບຂອງທ່ານ.
- ເພີ່ມແທັກ rel=”canonical” – ແທັກນີ້ແມ່ນ 'meta' ເວີຊັນ 301 redirect. ແທັກ "rel=canonical" ບອກ Google ເຊິ່ງເປັນ URL ຕົ້ນສະບັບສໍາລັບຫນ້າສະເພາະ. ສໍາລັບຕົວຢ່າງລະຫັດນີ້:
//example.com/original-page.html ” rel=”canonical” />
ບອກ Google ວ່າໜ້າເວັບ – original-page.html – ແມ່ນສະບັບ “ຕົ້ນສະບັບ” ຂອງໜ້າຊໍ້າກັນ. ຖ້າທ່ານໃຊ້ WordPress, ແທັກນີ້ແມ່ນງ່າຍທີ່ຈະເພີ່ມໂດຍໃຊ້ Yoast SEO ຫຼື All in One SEO.
ຖ້າທ່ານຕ້ອງການໃຫ້ຜູ້ເຂົ້າຊົມສາມາດເຂົ້າເຖິງເນື້ອຫາທີ່ຊ້ໍາກັນ, ໃຫ້ໃຊ້ rel=”canonical” tag. ຖ້າທ່ານບໍ່ຕ້ອງການໃຫ້ຜູ້ເຂົ້າຊົມຫຼື bots ເຂົ້າເຖິງເນື້ອຫາ - ໃຊ້ການປ່ຽນເສັ້ນທາງ 301.
ຈົ່ງລະມັດລະວັງການປະຕິບັດເພາະວ່າພວກມັນຈະສົ່ງຜົນກະທົບຕໍ່ SEO ຂອງທ່ານ.
ຕໍ່ກັບທ່ານ
ໄຟລ໌ Robots.txt ເປັນພັນທະມິດທີ່ເປັນປະໂຫຍດໃນການສ້າງວິທີທີ່ເຄື່ອງຈັກຊອກຫາ spider ແລະ bots ອື່ນໆພົວພັນກັບເວັບໄຊທ໌ຂອງທ່ານ. ເມື່ອຖືກນໍາໃຊ້ຢ່າງຖືກຕ້ອງ, ພວກເຂົາສາມາດມີຜົນກະທົບທາງບວກຕໍ່ການຈັດອັນດັບຂອງທ່ານແລະເຮັດໃຫ້ເວັບໄຊທ໌ຂອງທ່ານງ່າຍຕໍ່ການລວບລວມຂໍ້ມູນ.
ໃຊ້ຄູ່ມືນີ້ເພື່ອເຂົ້າໃຈວິທີການເຮັດວຽກຂອງ Robots.txt, ການຕິດຕັ້ງມັນແນວໃດແລະບາງວິທີທົ່ວໄປທີ່ທ່ານສາມາດນໍາໃຊ້ມັນ. . ແລະຫຼີກເວັ້ນການຜິດພາດໃດໆທີ່ພວກເຮົາໄດ້ສົນທະນາຂ້າງເທິງ.
ການອ່ານທີ່ກ່ຽວຂ້ອງ:
- ເຄື່ອງມືຕິດຕາມອັນດັບທີ່ດີທີ່ສຸດສໍາລັບບລັອກເກີ, ເມື່ອປຽບທຽບກັບ
- ຄໍາແນະນໍາທີ່ແນ່ນອນໃນການໄດ້ຮັບ Google Sitelinks
- 5 ເຄື່ອງມືຄົ້ນຄວ້າຄໍາສໍາຄັນທີ່ມີປະສິດທິພາບທຽບກັບ
 ຕ້ອງປະຕິບັດຕາມ. ມາດຕະຖານເຫຼົ່ານີ້ໄດ້ຖືກສະເໜີຂຶ້ນມາເປັນຄັ້ງທຳອິດໃນເດືອນກຸມພາ 1994.
ຕ້ອງປະຕິບັດຕາມ. ມາດຕະຖານເຫຼົ່ານີ້ໄດ້ຖືກສະເໜີຂຶ້ນມາເປັນຄັ້ງທຳອິດໃນເດືອນກຸມພາ 1994.ໃນວັນທີ 30 ມິຖຸນາ 1994, ຜູ້ຂຽນຫຸ່ນຍົນຈຳນວນໜຶ່ງ ແລະຜູ້ບຸກເບີກເວັບໃນຍຸກທຳອິດໄດ້ເປັນເອກະສັນກັນກ່ຽວກັບມາດຕະຖານດັ່ງກ່າວ.
ມາດຕະຖານເຫຼົ່ານີ້ໄດ້ຖືກຮັບຮອງເອົາເປັນ “ການຍົກເວັ້ນຫຸ່ນຍົນ. Protocol” (REP).
ໄຟລ໌ Robots.txt ແມ່ນການຈັດຕັ້ງປະຕິບັດໂປຣໂຕຄໍນີ້.
REP ກຳນົດກົດລະບຽບທີ່ທຸກຕົວກວາດເວັບ ຫຼື spider ທີ່ຖືກຕ້ອງຕາມກົດໝາຍຕ້ອງປະຕິບັດຕາມ. ຖ້າ Robots.txt ແນະນໍາຫຸ່ນຍົນບໍ່ໃຫ້ດັດສະນີຫນ້າເວັບ, ທຸກໆຫຸ່ນຍົນທີ່ຖືກຕ້ອງ - ຈາກ Googlebot ຫາ MSNbot - ຕ້ອງເຮັດຕາມຄໍາແນະນໍາ.
ຫມາຍເຫດ: ບັນຊີລາຍຊື່ຂອງຕົວລວບລວມຂໍ້ມູນທີ່ຖືກຕ້ອງຕາມກົດຫມາຍສາມາດ ພົບເຫັນຢູ່ບ່ອນນີ້.
ຈື່ໄວ້ວ່າບາງຫຸ່ນຍົນທີ່ຮ້າຍກາດ – ມັລແວ, ສະປາຍແວ, ເຄື່ອງເກັບກ່ຽວອີເມລ໌, ແລະອື່ນໆ – ອາດຈະບໍ່ປະຕິບັດຕາມໂປຣໂຕຄໍເຫຼົ່ານີ້. ນີ້ແມ່ນເຫດຜົນທີ່ທ່ານອາດຈະເຫັນການຈາລະຈອນຂອງ bot ໃນຫນ້າເວັບຕ່າງໆທີ່ທ່ານໄດ້ບລັອກຜ່ານ Robots.txt.
ຍັງມີຫຸ່ນຍົນທີ່ບໍ່ປະຕິບັດຕາມມາດຕະຖານ REP ທີ່ບໍ່ໄດ້ໃຊ້ສໍາລັບສິ່ງທີ່ເປັນຄໍາຖາມ.
ທ່ານສາມາດເບິ່ງ robots.txt ຂອງເວັບໄຊທ໌ໃດກໍໄດ້ໂດຍການໄປທີ່ url ນີ້:
//[website_domain]/robots.txt
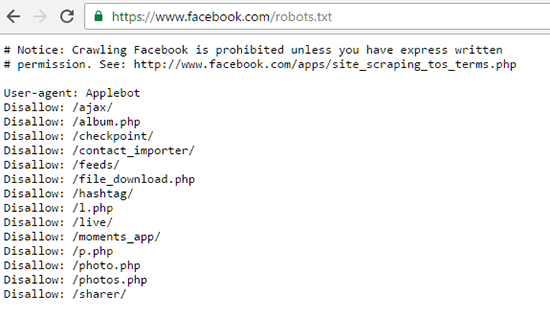
ຕົວຢ່າງ, ນີ້ແມ່ນໄຟລ໌ Robots.txt ຂອງ Facebook:
ແລະນີ້ແມ່ນໄຟລ໌ Robots.txt ຂອງ Google:

ການນຳໃຊ້ Robots.txt
Robots.txt ບໍ່ແມ່ນເອກະສານສຳຄັນສຳລັບເວັບໄຊທ໌. ເວັບໄຊຂອງທ່ານສາມາດຈັດອັນດັບ ແລະເຕີບໂຕໄດ້ດີເລີດໂດຍບໍ່ມີໄຟລ໌ນີ້.
ຢ່າງໃດກໍຕາມ, ການໃຊ້ Robots.txt ໃຫ້ຜົນປະໂຫຍດບາງຢ່າງ:
- ຂັດຂວາງບອທ໌ຈາກການລວບລວມຂໍ້ມູນໂຟນເດີສ່ວນຕົວ – ເຖິງແມ່ນວ່າບໍ່ສົມບູນແບບ, ການບໍ່ອະນຸຍາດໃຫ້ bots ຈາກການລວບລວມຂໍ້ມູນໂຟນເດີສ່ວນຕົວຈະເຮັດໃຫ້ພວກເຂົາຍາກທີ່ຈະດັດສະນີ - ຢ່າງຫນ້ອຍໂດຍ bots ທີ່ຖືກຕ້ອງ (ເຊັ່ນ: spider ເຄື່ອງຈັກຊອກຫາ).
- ຄວບຄຸມການໃຊ້ຊັບພະຍາກອນ – ທຸກໆຄັ້ງທີ່ bot ລວບລວມເວັບໄຊຂອງເຈົ້າ, ມັນຈະລະບາຍແບນວິດແລະຊັບພະຍາກອນຂອງເຄື່ອງແມ່ຂ່າຍຂອງທ່ານ - ຊັບພະຍາກອນທີ່ຈະໃຊ້ໄດ້ດີກວ່າສໍາລັບນັກທ່ອງທ່ຽວທີ່ແທ້ຈິງ. ສໍາລັບສະຖານທີ່ທີ່ມີເນື້ອຫາຫຼາຍ, ນີ້ສາມາດເພີ່ມຄ່າໃຊ້ຈ່າຍແລະໃຫ້ນັກທ່ອງທ່ຽວທີ່ແທ້ຈິງມີປະສົບການທີ່ບໍ່ດີ. ທ່ານສາມາດນໍາໃຊ້ Robots.txt ເພື່ອສະກັດການເຂົ້າເຖິງສະຄິບ, ຮູບພາບທີ່ບໍ່ສໍາຄັນ, ແລະອື່ນໆເພື່ອອະນຸລັກຊັບພະຍາກອນ.
- ຈັດລໍາດັບຄວາມສໍາຄັນຂອງຫນ້າ - ທ່ານຕ້ອງການ spider ເຄື່ອງຈັກຊອກຫາລວບລວມຫນ້າທີ່ສໍາຄັນຢູ່ໃນເວັບໄຊຂອງທ່ານ. (ເຊັ່ນ: ຫນ້າເນື້ອຫາ), ບໍ່ເສຍຊັບພະຍາກອນທີ່ຂຸດຄົ້ນຜ່ານຫນ້າທີ່ບໍ່ມີປະໂຫຍດ (ເຊັ່ນ: ຜົນໄດ້ຮັບຈາກຄໍາຖາມຄົ້ນຫາ). ໂດຍການປິດກັ້ນຫນ້າເວັບທີ່ບໍ່ມີປະໂຫຍດດັ່ງກ່າວ, ທ່ານສາມາດຈັດລໍາດັບຄວາມສໍາຄັນຂອງຫນ້າທີ່ bots ສຸມໃສ່.
ວິທີການຊອກຫາໄຟລ໌ Robots.txt ຂອງທ່ານ
ຕາມຊື່ແນະນໍາ, Robots.txt ແມ່ນງ່າຍດາຍ ໄຟລ໌ຂໍ້ຄວາມ.
ໄຟລ໌ນີ້ຖືກເກັບໄວ້ໃນລະບົບຮາກຂອງເວັບໄຊທ໌ຂອງທ່ານ. ເພື່ອຊອກຫາມັນ, ພຽງແຕ່ເປີດເຄື່ອງມື FTP ຂອງທ່ານແລະທ່ອງໄປຫາໄດເລກະທໍລີເວັບໄຊທ໌ຂອງທ່ານພາຍໃຕ້ public_html.

ນີ້ແມ່ນໄຟລ໌ຂໍ້ຄວາມຂະຫນາດນ້ອຍ - ຂອງຂ້ອຍແມ່ນພຽງແຕ່ຫຼາຍກວ່າ 100 bytes.
ເພື່ອເປີດມັນ. , ໃຊ້ຕົວແກ້ໄຂຂໍ້ຄວາມ, ເຊັ່ນ Notepad. ທ່ານອາດຈະເຫັນບາງສິ່ງບາງຢ່າງເຊັ່ນນີ້:

ມີໂອກາດທີ່ທ່ານຈະບໍ່ເຫັນໄຟລ໌ Robots.txt ໃນໄດເລກະທໍລີຮາກຂອງເວັບໄຊທ໌ຂອງທ່ານ. ໃນກໍລະນີດັ່ງກ່າວນີ້, ທ່ານຈະຕ້ອງສ້າງໄຟລ໌ Robots.txt ດ້ວຍຕົວທ່ານເອງ.
ນີ້ແມ່ນວິທີ:
ວິທີສ້າງໄຟລ໌ Robot.txt
ເນື່ອງຈາກ Robots.txt ເປັນໄຟລ໌ຂໍ້ຄວາມພື້ນຖານ, ການສ້າງມັນງ່າຍຫຼາຍ. – ພຽງແຕ່ເປີດຕົວແກ້ໄຂຂໍ້ຄວາມແລະບັນທຶກໄຟລ໌ເປົ່າເປັນ robots.txt.

ເພື່ອອັບໂຫລດໄຟລ໌ນີ້ກັບເຊີບເວີຂອງທ່ານ, ໃຊ້ເຄື່ອງມື FTP ທີ່ທ່ານມັກ (ຂ້າພະເຈົ້າແນະນໍາໃຫ້ໃຊ້ WinSCP) ເຂົ້າສູ່ລະບົບເວັບໄຊຕ໌ຂອງທ່ານ . ຫຼັງຈາກນັ້ນ, ເປີດໂຟນເດີ public_html ແລະເປີດໄດເລກະທໍລີຮາກຂອງເວັບໄຊທ໌ຂອງທ່ານ.
ຂຶ້ນກັບວິທີການທີ່ໂຮດເວັບຂອງທ່ານຖືກຕັ້ງຄ່າ, ໄດເລກະທໍລີຮາກຂອງເວັບໄຊທ໌ຂອງທ່ານອາດຈະຢູ່ໃນໂຟນເດີ public_html ໂດຍກົງ. ຫຼື, ມັນອາດຈະເປັນໂຟນເດີທີ່ຢູ່ໃນນັ້ນ.
ເມື່ອທ່ານເປີດໄດເລກະທໍລີຮາກຂອງເວັບໄຊທ໌ຂອງທ່ານແລ້ວ, ພຽງແຕ່ລາກ & ວາງໄຟລ໌ Robots.txt ໃສ່ມັນ.

ອີກທາງເລືອກໜຶ່ງ, ທ່ານສາມາດສ້າງໄຟລ໌ Robots.txt ໄດ້ໂດຍກົງຈາກຕົວແກ້ໄຂ FTP ຂອງທ່ານ.
ເບິ່ງ_ນຳ: ວິທີການຮັບຜູ້ຕິດຕາມເພີ່ມເຕີມໃນ Pinterest (ສະບັບ 2023)ເພື່ອເຮັດອັນນີ້, ເປີດໄດເລກະທໍລີຮາກຂອງເວັບໄຊຂອງເຈົ້າ ແລະ ຄລິກຂວາ -> ສ້າງໄຟລ໌ໃໝ່.
ໃນກ່ອງໂຕ້ຕອບ, ພິມ “robots.txt” (ໂດຍບໍ່ມີການອ້າງອີງ) ແລະກົດ OK.

ທ່ານຄວນຈະເຫັນໄຟລ໌ robots.txt ໃໝ່ພາຍໃນ:

ສຸດທ້າຍ, ໃຫ້ແນ່ໃຈວ່າທ່ານໄດ້ກໍານົດສິດອະນຸຍາດໄຟລ໌ທີ່ເຫມາະສົມສໍາລັບໄຟລ໌ Robots.txt. ທ່ານຕ້ອງການໃຫ້ເຈົ້າຂອງ - ຕົວທ່ານເອງ - ອ່ານແລະຂຽນໄຟລ໌, ແຕ່ບໍ່ໃຫ້ຄົນອື່ນຫຼືສາທາລະນະ.
ໄຟລ໌ Robots.txt ຂອງທ່ານຄວນສະແດງ “0644” ເປັນລະຫັດການອະນຸຍາດ.
ຖ້າ ມັນບໍ່ເປັນຫຍັງ, ຄລິກຂວາໃສ່ໄຟລ໌ Robots.txt ຂອງເຈົ້າ ແລະເລືອກ “ການອະນຸຍາດໄຟລ໌…”

ຢູ່ທີ່ນັ້ນ ເຈົ້າມີມັນ – ເປັນໄຟລ໌ Robots.txt ທີ່ມີປະໂຫຍດເຕັມທີ່!
ແຕ່ເຈົ້າສາມາດເຮັດຫຍັງໄດ້ກັບໄຟລ໌ນີ້?
ຕໍ່ໄປ, ຂ້ອຍຈະສະແດງຄຳແນະນຳທົ່ວໄປທີ່ເຈົ້າສາມາດໃຊ້ເພື່ອຄວບຄຸມການເຂົ້າເຖິງເວັບໄຊຂອງເຈົ້າໄດ້.
ວິທີໃຊ້ Robots.txt
ຈື່ໄວ້ວ່າ Robots.txt ຄວບຄຸມວິທີການທີ່ຫຸ່ນຍົນພົວພັນກັບເວັບໄຊຂອງເຈົ້າ.
ຕ້ອງການບລັອກເຄື່ອງຈັກຊອກຫາບໍ່ໃຫ້ເຂົ້າເຖິງເວັບໄຊທັງໝົດຂອງເຈົ້າບໍ? ພຽງແຕ່ປ່ຽນການອະນຸຍາດໃນ Robots.txt.
ຕ້ອງການທີ່ຈະບລັອກ Bing ຈາກການສ້າງຫນ້າຕິດຕໍ່ພົວພັນຂອງທ່ານ? ທ່ານສາມາດເຮັດໄດ້ຄືກັນ.
ໂດຍຕົວມັນເອງ, ໄຟລ໌ Robots.txt ຈະບໍ່ປັບປຸງ SEO ຂອງທ່ານ, ແຕ່ທ່ານສາມາດໃຊ້ມັນເພື່ອຄວບຄຸມພຶດຕິກໍາຕົວກວາດເວັບຢູ່ໃນເວັບໄຊຂອງທ່ານໄດ້.
ເພື່ອເພີ່ມ ຫຼືແກ້ໄຂ ໄຟລ໌, ພຽງແຕ່ເປີດມັນຢູ່ໃນບັນນາທິການ FTP ຂອງທ່ານແລະເພີ່ມຂໍ້ຄວາມໂດຍກົງ. ເມື່ອທ່ານບັນທຶກໄຟລ໌, ການປ່ຽນແປງຈະຖືກສະແດງໃນທັນທີ.
ນີ້ແມ່ນບາງຄໍາສັ່ງທີ່ທ່ານສາມາດນໍາໃຊ້ໃນໄຟລ໌ Robots.txt ຂອງທ່ານ:
1. ບລັອກບອທ໌ທັງໝົດຈາກເວັບໄຊຂອງເຈົ້າ
ຕ້ອງການບລັອກຫຸ່ນຍົນທັງໝົດຈາກການລວບລວມຂໍ້ມູນເວັບໄຊຂອງເຈົ້າບໍ?
ເບິ່ງ_ນຳ: ການທົບທວນຄືນ RafflePress 2023: ມັນເປັນ Plugin ການແຂ່ງຂັນ WordPress ທີ່ດີທີ່ສຸດບໍ?ເພີ່ມລະຫັດນີ້ໃສ່ໄຟລ໌ Robots.txt ຂອງທ່ານ:
User-agent: *Disallow: /
ນີ້ຄືສິ່ງທີ່ມັນຈະ ເບິ່ງຄືວ່າຢູ່ໃນໄຟລ໌ຕົວຈິງ:

ເວົ້າງ່າຍໆ, ຄໍາສັ່ງນີ້ບອກທຸກຕົວແທນຜູ້ໃຊ້ (*) ບໍ່ໃຫ້ເຂົ້າເຖິງໄຟລ໌ຫຼືໂຟນເດີໃດໆຢູ່ໃນເວັບໄຊຂອງທ່ານ.
ນີ້ແມ່ນຄົບຖ້ວນສົມບູນ. ຄໍາອະທິບາຍກ່ຽວກັບສິ່ງທີ່ເກີດຂຶ້ນຢູ່ທີ່ນີ້:
- User-agent:* – ເຄື່ອງໝາຍດາວ (*) ແມ່ນຕົວອັກສອນ 'wild-card' ທີ່ໃຊ້ກັບ ທຸກໆ object (ເຊັ່ນ: ຊື່ໄຟລ໌ ຫຼືໃນກໍລະນີນີ້, bot). ຖ້າທ່ານຊອກຫາ “*.txt” ໃນຄອມພິວເຕີຂອງທ່ານ, ມັນຈະສະແດງທຸກໄຟລ໌ດ້ວຍສ່ວນຂະຫຍາຍ .txt. ທີ່ນີ້, ເຄື່ອງຫມາຍດາວຫມາຍຄວາມວ່າຄໍາສັ່ງຂອງທ່ານໃຊ້ກັບ ທຸກໆ user-agent.
- Disallow: / – “Disallow” ແມ່ນຄໍາສັ່ງ robots.txt ຫ້າມ bot ຈາກ ລວບລວມໂຟນເດີ. ຂີດຕໍ່ໜ້າດຽວ (/) ໝາຍຄວາມວ່າທ່ານກຳລັງນຳໃຊ້ຄຳສັ່ງນີ້ກັບລະບົບຮາກ. ເວັບໄຊສະມາຊິກ. ແຕ່ຈົ່ງຮູ້ວ່ານີ້ຈະຢຸດ bots ທີ່ຖືກຕ້ອງຕາມກົດຫມາຍທັງຫມົດເຊັ່ນ Google ຈາກການລວບລວມຂໍ້ມູນເວັບໄຊທ໌ຂອງທ່ານ. ໃຊ້ດ້ວຍຄວາມລະມັດລະວັງ.
2. ບລັອກບອທ໌ທັງໝົດບໍ່ໃຫ້ເຂົ້າເຖິງໂຟນເດີສະເພາະ
ຈະເຮັດແນວໃດຫາກທ່ານຕ້ອງການປ້ອງກັນບໍ່ໃຫ້ບັອດລວບລວມຂໍ້ມູນ ແລະດັດສະນີໂຟນເດີສະເພາະ?
ຕົວຢ່າງ, ໂຟນເດີ /images?
ໃຊ້ ຄໍາສັ່ງນີ້:
User-agent: *
Disallow: /[folder_name]/
ຖ້າທ່ານຕ້ອງການຢຸດ bots ຈາກການເຂົ້າເຖິງໂຟເດີ /images, ນີ້ແມ່ນສິ່ງທີ່ຄໍາສັ່ງຈະຄ້າຍຄື:

ຄໍາສັ່ງນີ້ເປັນປະໂຫຍດຖ້າທ່ານມີໂຟນເດີຊັບພະຍາກອນ. ວ່າທ່ານບໍ່ຕ້ອງການ overwhelm ກັບຄໍາຮ້ອງຂໍຕົວກວາດເວັບຫຸ່ນຍົນ. ອັນນີ້ສາມາດເປັນໂຟນເດີທີ່ມີສະຄຣິບທີ່ບໍ່ສຳຄັນ, ຮູບພາບທີ່ລ້າສະໄຫມ, ແລະອື່ນໆ.
ໝາຍເຫດ: ໂຟນເດີ /images ແມ່ນຕົວຢ່າງທັງໝົດ. ຂ້າພະເຈົ້າບໍ່ໄດ້ເວົ້າວ່າທ່ານຄວນສະກັດ bots ຈາກການລວບລວມຂໍ້ມູນໂຟນເດີນັ້ນ. ມັນຂຶ້ນກັບສິ່ງທີ່ເຈົ້າກຳລັງພະຍາຍາມບັນລຸ.
ໂດຍທົ່ວໄປແລ້ວ ເຄື່ອງຈັກຊອກຫາຈະໜ້າງຶດໃສ່ຜູ້ຄຸ້ມຄອງເວັບທີ່ປິດກັ້ນ bots ຂອງເຂົາເຈົ້າຈາກການລວບລວມຂໍ້ມູນໂຟນເດີທີ່ບໍ່ແມ່ນຮູບພາບ, ສະນັ້ນ ຈົ່ງລະມັດລະວັງເມື່ອທ່ານໃຊ້ຄຳສັ່ງນີ້. ຂ້ອຍໄດ້ລະບຸບາງທາງເລືອກໃຫ້ກັບ Robots.txt ສໍາລັບການຢຸດເຄື່ອງຈັກຊອກຫາດັດສະນີໜ້າສະເພາະທາງລຸ່ມ.
3. ບລັອກບອທ໌ສະເພາະຈາກເວັບໄຊຂອງເຈົ້າ
ຈະເຮັດແນວໃດຫາກທ່ານຕ້ອງການບລັອກຫຸ່ນຍົນສະເພາະ – ເຊັ່ນ Googlebot – ບໍ່ໃຫ້ເຂົ້າເຖິງເວັບໄຊຂອງເຈົ້າ?
ນີ້ແມ່ນຄໍາສັ່ງສໍາລັບມັນ:
User-agent: [robot name]
Disallow: /
ຕົວຢ່າງ: ຖ້າທ່ານຕ້ອງການບລັອກ Googlebot ຈາກເວັບໄຊຂອງເຈົ້າ, ນີ້ແມ່ນສິ່ງທີ່ເຈົ້າຈະໃຊ້:

ແຕ່ລະ bot ທີ່ຖືກຕ້ອງຕາມກົດໝາຍ ຫຼືຕົວແທນຜູ້ໃຊ້ມີຊື່ສະເພາະ. ສໍາລັບຕົວຢ່າງ, ແມງມຸມຂອງ Google ຖືກເອີ້ນວ່າ "Googlebot". Microsoft ແລ່ນທັງ "msnbot" ແລະ "bingbot". bot ຂອງ Yahoo ຖືກເອີ້ນວ່າ "Yahoo! Slurp”.
ເພື່ອຊອກຫາຊື່ແທ້ຂອງຕົວແທນຜູ້ໃຊ້ທີ່ແຕກຕ່າງກັນ (ເຊັ່ນ: Googlebot, bingbot, ແລະອື່ນໆ) ໃຫ້ໃຊ້ໜ້ານີ້.
ໝາຍເຫດ: ຄຳສັ່ງຂ້າງເທິງຈະ ສະກັດ bot ສະເພາະຈາກເວັບໄຊທ໌ທັງຫມົດຂອງທ່ານ. Googlebot ຖືກນໍາໃຊ້ຢ່າງດຽວເປັນຕົວຢ່າງ. ໃນກໍລະນີຫຼາຍທີ່ສຸດ, ທ່ານຈະບໍ່ຕ້ອງການທີ່ຈະຢຸດ Google ຈາກການລວບລວມເວັບໄຊທ໌ຂອງທ່ານ. ກໍລະນີການນໍາໃຊ້ສະເພາະຫນຶ່ງສໍາລັບການສະກັດ bots ສະເພາະແມ່ນເພື່ອຮັກສາ bots ທີ່ເປັນປະໂຫຍດທີ່ທ່ານເຂົ້າມາໃນເວັບໄຊຂອງທ່ານ, ໃນຂະນະທີ່ຢຸດເຊົາການທີ່ບໍ່ໄດ້ຮັບຜົນປະໂຫຍດເວັບໄຊຂອງທ່ານ.
4. ບລັອກໄຟລ໌ສະເພາະຈາກການຖືກກວາດເວັບ
ໂປຣໂຕຄອນການຍົກເວັ້ນຫຸ່ນຍົນຈະໃຫ້ທ່ານຄວບຄຸມໄດ້ຢ່າງດີວ່າໄຟລ໌ໃດ ແລະໂຟນເດີໃດທີ່ທ່ານຕ້ອງການບລັອກການເຂົ້າເຖິງຂອງຫຸ່ນຍົນ.
ນີ້ແມ່ນຄຳສັ່ງທີ່ທ່ານສາມາດໃຊ້ເພື່ອຢຸດໄຟລ໌ໃດໜຶ່ງໄດ້. ຈາກການຖືກກວາດໂດຍຫຸ່ນຍົນໃດໆ:
User-agent: *
Disallow: /[folder_name]/[file_name.extension]
ດັ່ງນັ້ນ, ຖ້າທ່ານຕ້ອງການບລັອກໄຟລ໌ທີ່ມີຊື່ວ່າ “img_0001.png” ຈາກໂຟນເດີ “images”, ເຈົ້າຄວນໃຊ້ຄໍາສັ່ງນີ້:

5. ຂັດຂວາງການເຂົ້າເຖິງໂຟນເດີແຕ່ອະນຸຍາດໃຫ້ໄຟລ໌ເປັນindexed
ຄໍາສັ່ງ “Disallow” ຂັດຂວາງ bots ຈາກການເຂົ້າເຖິງໂຟນເດີຫຼືໄຟລ໌.
ຄໍາສັ່ງ “Allow” ເຮັດກົງກັນຂ້າມ.
ຄໍາສັ່ງ “Allow” ແທນທີ່. ຄຳສັ່ງ “ບໍ່ອະນຸຍາດ” ຖ້າອະດີດຕັ້ງເປົ້າໝາຍໃສ່ໄຟລ໌ບຸກຄົນ.
ນີ້ໝາຍຄວາມວ່າທ່ານສາມາດບລັອກການເຂົ້າເຖິງໂຟນເດີໃດໜຶ່ງໄດ້ ແຕ່ອະນຸຍາດໃຫ້ຕົວແທນຜູ້ໃຊ້ຍັງເຂົ້າເຖິງໄຟລ໌ສ່ວນບຸກຄົນພາຍໃນໂຟນເດີໄດ້.
ນີ້ແມ່ນ ຮູບແບບທີ່ຈະໃຊ້:
User-agent: *
Disallow: /[folder_name]/
Allow: /[folder_name]/[file_name.extension]/
ຕົວຢ່າງ, ຖ້າທ່ານຕ້ອງການປິດກັ້ນ Google ຈາກການລວບລວມຂໍ້ມູນໂຟນເດີ "ຮູບພາບ" ແຕ່ຍັງຕ້ອງການໃຫ້ມັນເຂົ້າເຖິງໄຟລ໌ "img_0001.png" ທີ່ເກັບໄວ້ໃນນັ້ນ, ນີ້ແມ່ນຮູບແບບທີ່ທ່ານໄດ້. 'd ໃຊ້:
ສໍາລັບຕົວຢ່າງຂ້າງເທິງ, ມັນຈະເປັນແບບນີ້:

ນີ້ຈະຢຸດທຸກຫນ້າໃນ /search/ directory ຈາກການຖືກດັດສະນີ.
ເປັນແນວໃດຫາກທ່ານຕ້ອງການຢຸດທຸກໜ້າທີ່ກົງກັບສ່ວນຂະຫຍາຍສະເພາະ (ເຊັ່ນ: “.php” ຫຼື “.png”) ຈາກການຖືກດັດສະນີ?
ໃຊ້ອັນນີ້:
User-agent: *
Disallow: /*.extension$
The ($ ) ເຊັນທີ່ນີ້ໝາຍເຖິງຈຸດສິ້ນສຸດຂອງ URL, i.e. ສ່ວນຂະຫຍາຍແມ່ນສະຕຣິງສຸດທ້າຍໃນ URL.
ຫາກທ່ານຕ້ອງການບລັອກທຸກໜ້າດ້ວຍສ່ວນຂະຫຍາຍ “.js” (ສຳລັບ Javascript), ນີ້ແມ່ນສິ່ງທີ່ເຈົ້າຕ້ອງການ. ໃຊ້:

ຄຳສັ່ງນີ້ມີປະສິດທິພາບໂດຍສະເພາະຖ້າທ່ານຕ້ອງການຢຸດບອທ໌ຈາກການລວບລວມຂໍ້ມູນສະຄຣິບ.
6. ຢຸດ bots ຈາກການລວບລວມຂໍ້ມູນເວັບໄຊທ໌ຂອງທ່ານເລື້ອຍໆ
ໃນຕົວຢ່າງຂ້າງເທິງ, ທ່ານອາດຈະໄດ້ເຫັນຄໍາສັ່ງນີ້:
User-agent: *
Crawl-Delay: 20
ຄໍາສັ່ງນີ້ສັ່ງໃຫ້ bots ທັງຫມົດລໍຖ້າຢ່າງຫນ້ອຍ 20 ວິນາທີລະຫວ່າງຄໍາຮ້ອງຂໍການລວບລວມຂໍ້ມູນ.
ການລ່າຊ້າ-ການລ່າຊ້າຄໍາສັ່ງຖືກນໍາໃຊ້ເລື້ອຍໆຢູ່ໃນເວັບໄຊທ໌ຂະຫນາດໃຫຍ່ທີ່ມີເນື້ອຫາທີ່ຖືກປັບປຸງເລື້ອຍໆ (ເຊັ່ນ Twitter). ຄໍາສັ່ງນີ້ບອກ bots ໃຫ້ລໍຖ້າຈໍານວນຕໍາ່ສຸດທີ່ລະຫວ່າງການຮ້ອງຂໍຕໍ່ໄປ.
ນີ້ຮັບປະກັນວ່າເຄື່ອງແມ່ຂ່າຍບໍ່ໄດ້ overwhelmed ກັບຄໍາຮ້ອງຂໍຫຼາຍເກີນໄປໃນເວລາດຽວກັນຈາກ bots ທີ່ແຕກຕ່າງກັນ.
ຕົວຢ່າງ. , ນີ້ແມ່ນໄຟລ໌ Robots.txt ຂອງ Twitter ທີ່ສັ່ງໃຫ້ bots ລໍຖ້າຢ່າງໜ້ອຍ 1 ວິນາທີລະຫວ່າງການຮ້ອງຂໍ:

ທ່ານຍັງສາມາດຄວບຄຸມການລ່າຊ້າການລວບລວມຂໍ້ມູນສໍາລັບ bots ສ່ວນບຸກຄົນ. ນີ້ຮັບປະກັນວ່າ bots ຫຼາຍເກີນໄປບໍ່ລວບລວມຂໍ້ມູນເວັບໄຊທ໌ຂອງທ່ານໃນເວລາດຽວກັນ.
ຕົວຢ່າງ, ທ່ານອາດຈະມີຊຸດຄໍາສັ່ງເຊັ່ນນີ້:

ຫມາຍເຫດ: ທ່ານຈະບໍ່ຈໍາເປັນຕ້ອງໃຊ້ຄໍາສັ່ງນີ້ແທ້ໆເວັ້ນເສຍແຕ່ວ່າທ່ານກໍາລັງດໍາເນີນການເວັບໄຊທ໌ໃຫຍ່ທີ່ມີຫນ້າໃຫມ່ຫຼາຍພັນຫນ້າທີ່ຖືກສ້າງຂື້ນທຸກໆນາທີ (ເຊັ່ນ Twitter).
ຄວາມຜິດພາດທົ່ວໄປທີ່ຈະຫຼີກເວັ້ນໃນເວລາທີ່ໃຊ້ Robots.txt
ໄຟລ໌ Robots.txt ເປັນເຄື່ອງມືທີ່ມີປະສິດທິພາບໃນການຄວບຄຸມພຶດຕິກໍາຂອງ bot ຢູ່ໃນເວັບໄຊຂອງເຈົ້າ.
ຢ່າງໃດກໍຕາມ, ມັນຍັງສາມາດນໍາໄປສູ່ໄພພິບັດ SEO ຖ້າໃຊ້ບໍ່ຖືກຕ້ອງ. ມັນບໍ່ໄດ້ຊ່ວຍໃຫ້ມີຄວາມເຂົ້າໃຈຜິດຫຼາຍໆຢ່າງກ່ຽວກັບ Robots.txt ລອຍຢູ່ໃນອອນໄລນ໌.
ນີ້ແມ່ນຄວາມຜິດພາດບາງອັນທີ່ເຈົ້າຕ້ອງຫຼີກເວັ້ນໃນເວລາໃຊ້ Robots.txt:
ຄວາມຜິດພາດ #1 – ການນໍາໃຊ້ Robots.txt ເພື່ອປ້ອງກັນບໍ່ໃຫ້ເນື້ອຫາຖືກດັດສະນີ
ຖ້າທ່ານ “ບໍ່ອະນຸຍາດ” ໂຟນເດີໃນໄຟລ໌ Robots.txt, ບັອດທີ່ຖືກຕ້ອງຈະບໍ່ລວບລວມຂໍ້ມູນມັນ.
ແຕ່, ອັນນີ້ຍັງໝາຍເຖິງສອງຢ່າງ. :
- ບັອດຈະລວບລວມຂໍ້ມູນຂອງ