Kas yra Robots.txt failas ir kaip jį sukurti? (Pradedančiųjų vadovas)

Turinys
Ar žinojote, kad galite visiškai kontroliuoti, kas nuskaito ir indeksuoja jūsų svetainę iki atskirų puslapių?
Tai atliekama per failą Robots.txt.
Robots.txt - tai paprastas tekstinis failas, esantis jūsų svetainės šakniniame kataloge. Jame robotams (pvz., paieškos sistemų vorams) nurodoma, kuriuos svetainės puslapius nuskaityti ir kuriuos ignoruoti.
Nors Robots.txt failas nėra būtinas, jis suteikia daug galimybių kontroliuoti, kaip "Google" ir kitos paieškos sistemos mato jūsų svetainę.
Tinkamai naudojant, tai gali pagerinti nuskaitymą ir netgi paveikti SEO.
Tačiau kaip tiksliai sukurti veiksmingą Robots.txt failą? Kaip juo naudotis, kai jis sukurtas? Ir kokių klaidų reikėtų vengti jį naudojant?
Šiame įraše pasidalinsiu viskuo, ką reikia žinoti apie Robots.txt failą ir kaip jį naudoti savo tinklaraštyje.
Pasinerkime:
Kas yra Robots.txt failas?
Dar ankstyvuoju interneto gyvavimo laikotarpiu programuotojai ir inžinieriai sukūrė "robotus" arba "vorus", kurie naršė ir indeksavo tinklalapius internete. Šie robotai dar vadinami "naudotojų agentais".
Kartais šie robotai patekdavo į puslapius, kurių svetainių savininkai nenorėjo, kad būtų indeksuojami, pavyzdžiui, į statomą svetainę arba privačią svetainę.
Siekdamas išspręsti šią problemą, olandų inžinierius Martijnas Kosteris, sukūręs pirmąją pasaulyje paieškos sistemą ("Aliweb"), pasiūlė standartų rinkinį, kurio turėtų laikytis kiekvienas robotas. 1994 m. vasario mėn. pirmą kartą šie standartai buvo pasiūlyti.
1994 m. birželio 30 d. daugelis robotų autorių ir ankstyvųjų žiniatinklio pradininkų susitarė dėl standartų.
Šie standartai buvo patvirtinti kaip "Robotų pašalinimo protokolas" (REP).
Robots.txt failas yra šio protokolo įgyvendinimo priemonė.
REP apibrėžia taisyklių rinkinį, kurio turi laikytis kiekvienas teisėtas naršyklė ar voras. Jei Robots.txt nurodo robotams neindeksuoti tinklalapio, kiekvienas teisėtas robotas - nuo "Googlebot" iki MSNbot - turi laikytis šių nurodymų.
Pastaba: Teisėtų naršyklių sąrašą rasite čia.
Atminkite, kad kai kurie nesąžiningi robotai - kenkėjiškos ir šnipinėjimo programos, el. laiškų surinkėjai ir t. t. - gali nesilaikyti šių protokolų. Todėl puslapiuose, kuriuos užblokavote naudodami Robots.txt, gali būti matomas robotų srautas.
Taip pat yra robotų, kurie nesilaiko REP standartų ir kurie nenaudojami jokiems abejotiniems tikslams.
Bet kurios svetainės robots.txt galite peržiūrėti nuėję į šį URL adresą:
//[svetainės_domenas]/robots.txt
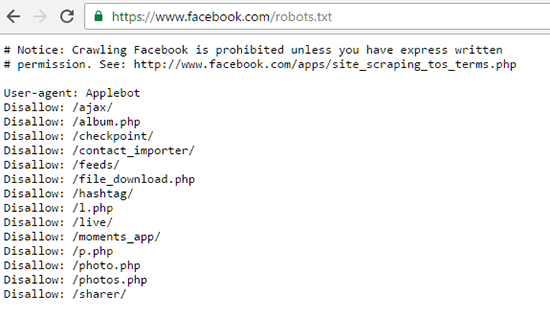
Pavyzdžiui, čia pateikiamas "Facebook" Robots.txt failas:
Čia pateikiamas "Google" Robots.txt failas:

Robots.txt naudojimas
Robots.txt nėra būtinas svetainės dokumentas. Jūsų svetainė gali būti puikiai vertinama ir augti be šio failo.
Tačiau Robots.txt naudojimas turi tam tikrų privalumų:
- Sulaikykite robotus nuo privačių aplankų naršymo - Nors tai ir nėra tobula, tačiau uždraudus robotams naršyti po privačius aplankus, juos bus daug sunkiau indeksuoti - bent jau teisėtiems robotams (pvz., paieškos sistemų vorams).
- Išteklių naudojimo kontrolė - Kiekvieną kartą, kai robotas nuskaito jūsų svetainę, jis eikvoja pralaidumą ir serverio išteklius - išteklius, kuriuos būtų geriau skirti tikriems lankytojams. Daug turinio turinčiose svetainėse tai gali padidinti sąnaudas ir suteikti tikriesiems lankytojams prastą patirtį. Norėdami taupyti išteklius, galite naudoti Robots.txt, kad užblokuotumėte prieigą prie skriptų, nesvarbių vaizdų ir kt.
- Nustatykite svarbių puslapių prioritetus - Norite, kad paieškos sistemų vorai naršytų svarbius svetainės puslapius (pvz., turinio puslapius), o ne eikvotų resursus nenaudingiems puslapiams (pvz., paieškos užklausų rezultatams). Užblokavę tokius nenaudingus puslapius, galite nustatyti prioritetus, į kuriuos puslapius robotai sutelks dėmesį.
Kaip rasti Robots.txt failą
Kaip matyti iš pavadinimo, Robots.txt yra paprastas teksto failas.
Šis failas saugomas jūsų svetainės šakniniame kataloge. Norėdami jį rasti, tiesiog atidarykite FTP įrankį ir eikite į savo svetainės katalogą public_html.

Tai mažytis teksto failas - mano yra vos daugiau nei 100 baitų.
Norėdami jį atidaryti, naudokite bet kurį teksto redaktorių, pvz., "Notepad":

Gali būti, kad svetainės šakniniame kataloge nematysite jokio Robots.txt failo. Tokiu atveju turėsite patys sukurti Robots.txt failą.
Štai kaip:
Kaip sukurti Robot.txt failą
Kadangi robots.txt yra paprastas tekstinis failas, jį sukurti labai paprasta - tiesiog atidarykite teksto redaktorių ir išsaugokite tuščią failą kaip robots.txt.

Norėdami įkelti šį failą į serverį, naudodami mėgstamą FTP įrankį (rekomenduoju naudoti "WinSCP") prisijunkite prie savo žiniatinklio serverio. Tada atidarykite aplanką public_html ir atverkite svetainės šakninį katalogą.
Priklausomai nuo to, kaip sukonfigūruotas jūsų žiniatinklio prieglobos kompiuteris, jūsų svetainės šakninis katalogas gali būti tiesiogiai aplanke public_html arba jo viduje.
Atidarę svetainės šakninį katalogą, tiesiog vilkite ir į jį įmeskite Robots.txt failą.

Arba galite sukurti Robots.txt failą tiesiogiai iš FTP redaktoriaus.
Norėdami tai padaryti, atidarykite svetainės šakninį katalogą ir dešiniuoju pelės mygtuku spustelėkite -> Sukurti naują failą.
Dialogo lange įveskite "robots.txt" (be kabučių) ir paspauskite OK.

Turėtumėte pamatyti naują robots.txt failą:

Galiausiai įsitikinkite, kad nustatėte tinkamą Robots.txt failo leidimą. Norite, kad failą galėtų skaityti ir rašyti jo savininkas - jūs patys, bet ne kiti asmenys ar visuomenė.
Jūsų Robots.txt faile turėtų būti nurodytas leidimo kodas "0644".
Jei taip nėra, dešiniuoju pelės klavišu spustelėkite Robots.txt failą ir pasirinkite "Failų leidimai..."

Štai jis - visiškai funkcionalus Robots.txt failas!
Tačiau ką iš tikrųjų galite daryti su šiuo failu?
Toliau pateiksiu keletą bendrų nurodymų, kuriuos galite naudoti prieigai prie svetainės kontroliuoti.
Kaip naudoti Robots.txt
Atminkite, kad Robots.txt iš esmės kontroliuoja, kaip robotai sąveikauja su jūsų svetaine.
Jei norite, kad paieškos sistemos negalėtų pasiekti visos svetainės, tiesiog pakeiskite leidimus Robots.txt.
Norite užblokuoti "Bing", kad ši neindeksuotų jūsų kontaktų puslapio? Tai taip pat galite padaryti.
Pats savaime failas Robots.txt nepagerins jūsų SEO, tačiau galite jį naudoti norėdami kontroliuoti ropojančiųjų robotų elgesį svetainėje.
Norėdami pridėti ar pakeisti failą, tiesiog atidarykite jį FTP redaktoriuje ir tiesiogiai pridėkite tekstą. Išsaugojus failą, pakeitimai bus iš karto atspindėti.
Štai keletas komandų, kurias galite naudoti Robots.txt faile:
1. Užblokuokite visus robotus savo svetainėje
Norite užblokuoti visus robotus, kad jie nelandžiotų po jūsų svetainę?
Įrašykite šį kodą į Robots.txt failą:
Vartotojo agentas: *Neleisti: /
Štai kaip tai atrodytų faktiniame faile:

Paprasčiau tariant, šia komanda kiekvienam naudotojo agentui (*) nurodoma nesinaudoti jokiais jūsų svetainės failais ar aplankais.
Čia pateikiamas išsamus paaiškinimas, kas čia vyksta:
- Vartotojo agentas:* - Žvaigždutė (*) - tai simbolis "laukinė kortelė", taikomas kiekvienas objektą (pvz., failo pavadinimą arba šiuo atveju botą). Jei kompiuteryje ieškosite "*.txt", bus rodomi visi failai su plėtiniu .txt. Šiuo atveju žvaigždutė reiškia, kad jūsų komanda taikoma kiekvienas vartotojo agentas.
- Neleisti: / - "Disallow" yra robots.txt komanda, draudžianti robotui naršyti po aplanką. Vienas pasvirasis brūkšnys (/) reiškia, kad šią komandą taikote šakniniam katalogui.
Pastaba: Tai ideali priemonė, jei naudojate bet kokią privačią svetainę, pvz., narystės svetainę. Tačiau turėkite omenyje, kad dėl to visi teisėti robotai, pvz., "Google", negalės nuskaityti jūsų svetainės. Naudokite atsargiai.
2. Užblokuokite visų botų prieigą prie konkretaus aplanko
Ką daryti, jei norite neleisti robotams naršyti ir indeksuoti tam tikro aplanko?
Pavyzdžiui, aplankas /images?
Naudokite šią komandą:
Vartotojo agentas: *Neleisti: /[aplanko_vardas]/
Taip pat žr: 35+ Geriausi "Twitter" statistiniai duomenys 2023 m.
Jei norėtumėte sustabdyti botų prieigą prie /images aplanko, komanda atrodytų taip:

Ši komanda naudinga, jei turite išteklių aplanką, kurio nenorite perkrauti robotų roverių užklausomis. Tai gali būti aplankas su nesvarbiais scenarijais, pasenusiais paveikslėliais ir pan.
Pastaba: Aplankas /images yra tik pavyzdys. Nesakau, kad turėtumėte blokuoti robotus, kad jie nelįstų į šį aplanką. Tai priklauso nuo to, ką norite pasiekti.
Paieškos sistemos paprastai neigiamai vertina tai, kad tinklalapių valdytojai blokuoja savo robotus, kad jie neindexuotų ne vaizdų aplankų, todėl naudodami šią komandą būkite atsargūs. Toliau pateikiau keletą Robots.txt alternatyvų, kaip neleisti paieškos sistemoms indeksuoti konkrečių puslapių.
3. Užblokuokite konkrečius robotus savo svetainėje
Ką daryti, jei norite užblokuoti konkretaus roboto, pavyzdžiui, "Googlebot", prieigą prie svetainės?
Čia pateikiama jos komanda:
Vartotojo agentas: [roboto vardas]Neleisti: /
Pavyzdžiui, jei norėtumėte užblokuoti "Googlebot" prieigą prie savo svetainės, naudokite šią funkciją:
Taip pat žr: 8 geriausios nemokamos internetinės portfelio prieglobos svetainės 2023 m.
Kiekvienas teisėtas robotas arba naudotojo agentas turi konkretų pavadinimą. Pavyzdžiui, "Google" voras vadinamas tiesiog "Googlebot". "Microsoft" naudoja ir "msnbot", ir "bingbot". "Yahoo" robotas vadinamas "Yahoo! Slurp".
Norėdami sužinoti tikslius įvairių naudotojų agentų (pvz., "Googlebot", "bingbot" ir kt.) pavadinimus, naudokitės šiuo puslapiu.
Pastaba: Pirmiau pateikta komanda užblokuotų konkretų robotą visoje jūsų svetainėje. Googlebot naudojamas tik kaip pavyzdys. Daugeliu atvejų niekada nenorėtumėte sustabdyti Google naršymo jūsų svetainėje. Vienas iš konkrečių konkrečių robotų blokavimo atvejų yra tas, kad į jūsų svetainę ateitų jums naudingi robotai, o tie, kurie neduoda naudos jūsų svetainei, būtų sustabdyti.
4. Užblokuokite konkretų failą nuo naršymo
Robotų pašalinimo protokolas leidžia tiksliai kontroliuoti, prie kurių failų ir aplankų norite blokuoti robotų prieigą.
Čia pateikiama komanda, kurią galite naudoti norėdami sustabdyti bet kurio roboto ropojimą po failą:
Vartotojo agentas: *Neleisti: /[aplanko_pavadinimas]/[failo_pavadinimas.plėtinys]
Taigi, jei norite užblokuoti failą pavadinimu "img_0001.png" iš aplanko "images", naudokite šią komandą:

5. Užblokuoti prieigą prie aplanko, bet leisti indeksuoti failą
Komanda "Disallow" blokuoja botų prieigą prie aplanko arba failo.
Komanda "Leisti" veikia priešingai.
Komanda "Leisti" pakeičia komandą "Uždrausti", jei pirmoji skirta atskiram failui.
Tai reiškia, kad galite blokuoti prieigą prie aplanko, bet leisti naudotojų agentams vis tiek pasiekti atskirą aplanko failą.
Pateikiame tokį formatą:
Vartotojo agentas: *Neleisti: /[aplanko_vardas]/
Leisti: /[aplanko_vardas]/[failo_vardo.plėtinys]/
Pavyzdžiui, jei norite blokuoti "Google" naršymą aplanke "images", bet vis tiek norite suteikti prieigą prie jame saugomo failo "img_0001.png", naudokite šį formatą:
Pirmiau pateiktame pavyzdyje jis atrodytų taip:

Tai sustabdytų visų /search/ katalogo puslapių indeksavimą.
Ką daryti, jei norite, kad visi puslapiai, atitinkantys tam tikrą plėtinį (pvz., ".php" arba ".png"), nebūtų indeksuojami?
Naudokite tai:
Vartotojo agentas: *Neleisti: /*.extension$
Ženklas ($) reiškia URL adreso pabaigą, t. y. plėtinys yra paskutinė URL eilutė.
Jei norite blokuoti visus puslapius su plėtiniu ".js" (reiškiančiu "Javascript"), naudokite šį būdą:

Ši komanda ypač veiksminga, jei norite sustabdyti robotus, kad jie neperskaitytų scenarijų.
6. Sustabdykite robotus, kad jie per dažnai nelandžiotų po jūsų svetainę
Pirmiau pateiktuose pavyzdžiuose galėjote matyti šią komandą:
Vartotojo agentas: *Vėlavimas: 20
Ši komanda nurodo visiems robotams laukti mažiausiai 20 sekundžių tarp naršymo užklausų.
Komanda "Crawl-Delay" dažnai naudojama didelėse svetainėse, kurių turinys dažnai atnaujinamas (pvz., "Twitter"). Ši komanda nurodo robotams laukti minimalų laiko tarpą tarp vėlesnių užklausų.
Taip užtikrinama, kad serveris nebūtų perkrautas per daug užklausų vienu metu iš skirtingų robotų.
Pavyzdžiui, šiame "Twitter" Robots.txt faile nurodoma, kad robotai tarp užklausų turi laukti mažiausiai 1 sekundę:

Galite net valdyti atskirų robotų naršymo vėlavimą. Taip užtikrinama, kad per daug robotų vienu metu nepradėtų naršyti jūsų svetainės.
Pavyzdžiui, galite turėti tokį komandų rinkinį:

Pastaba: Šios komandos tikrai neprireiks, nebent naudojate didžiulę svetainę, kurioje kiekvieną minutę sukuriama tūkstančiai naujų puslapių (pvz., "Twitter").
Dažniausiai pasitaikančios klaidos, kurių reikia vengti naudojant Robots.txt
Robots.txt failas yra galingas įrankis, kuriuo galima kontroliuoti robotų elgesį jūsų svetainėje.
Tačiau neteisingai naudojama ji taip pat gali sukelti SEO katastrofą. Nepadeda ir tai, kad internete sklando daug klaidingų nuomonių apie Robots.txt.
Štai keletas klaidų, kurių turite vengti naudodami Robots.txt:
Klaida Nr. 1 - Robots.txt naudojimas siekiant neleisti indeksuoti turinio
Jei "Robots.txt" faile uždrausite aplanko naudojimą, teisėti robotai jo nelankys.
Tačiau tai vis tiek reiškia du dalykus:
- Botai peržiūrės aplanko turinį, į kurį yra nuorodos iš išorinių šaltinių. Tarkime, jei kitoje svetainėje bus nuoroda į failą, esantį jūsų užblokuotame aplanke, botai jį indeksuos.
- Piktavaliai robotai - spameriai, šnipinėjimo programos, kenkėjiškos programos ir kt. - paprastai ignoruoja Robots.txt nurodymus ir indeksuoja jūsų turinį neatsižvelgdami į juos.
Dėl to Robots.txt yra prasta priemonė, neleidžianti indeksuoti turinio.
Vietoj to turėtumėte naudoti žymą "meta noindex".
Į puslapius, kurių nenorite indeksuoti, įtraukite šią žymą:
Tai yra rekomenduojamas, SEO optimizavimui palankus būdas, kaip sustabdyti puslapio indeksavimą (nors jis vis tiek neužkerta kelio šlamšto siuntėjams).
Pastaba: Jei naudojate "WordPress" įskiepį, pavyzdžiui, "Yoast SEO" arba "All in One SEO", galite tai padaryti neredaguodami jokio kodo. Pavyzdžiui, "Yoast SEO" įskiepyje galite pridėti "noindex" žymą kiekvienam pranešimui / puslapiui, pvz., taip:

Tiesiog atidarykite pranešimą / puslapį ir spustelėkite "Yoast SEO" lange esantį ratuką. Tada spustelėkite išskleidžiamąjį langelį šalia "Meta robotų indeksas".
Be to, nuo rugsėjo 1 d. "Google" nebepalaikys "noindex" naudojimo robots.txt failuose. Daugiau informacijos pateikiama šiame SearchEngineLand straipsnyje.
Klaida Nr. 2 - Robots.txt naudojimas privačiam turiniui apsaugoti
Jei turite privataus turinio, pavyzdžiui, el. paštu siunčiamų kursų PDF failų, katalogo blokavimas naudojant "Robots.txt" failą padės, tačiau to nepakanka.
Štai kodėl:
Jūsų turinys vis tiek gali būti indeksuojamas, jei jis susietas iš išorinių šaltinių. Be to, nesąžiningi robotai vis tiek jį nuskaitys.
Geresnis būdas - visą privatų turinį laikyti už prisijungimo vardo. Taip užtikrinsite, kad niekas - nei teisėti, nei nesąžiningi robotai - negalės prieiti prie jūsų turinio.
Neigiama yra tai, kad lankytojams teks įveikti papildomą kliūtį. Tačiau jūsų turinys bus saugesnis.
Klaida Nr. 3 - Robots.txt naudojimas siekiant sustabdyti dubliuojančio turinio indeksavimą
Dubliuojantis turinys yra didelis "ne", kai kalbama apie SEO.
Tačiau "Robots.txt" naudojimas siekiant sustabdyti šio turinio indeksavimą nėra tinkamas sprendimas. Vėlgi, nėra jokios garantijos, kad paieškos sistemų vorai neras šio turinio per išorinius šaltinius.
Štai dar 3 būdai, kaip tvarkyti dubliuojantį turinį:
- Ištrinkite besidubliuojantį turinį - Taip visiškai atsikratysite turinio. Tačiau tai reiškia, kad paieškos sistemas nukreipsite į 404 puslapius - tai nėra idealu. Dėl šios priežasties, nerekomenduojama ištrinti. .
- Naudokite 301 nukreipimą - 301 nukreipimas nurodo paieškos sistemoms (ir lankytojams), kad puslapis perkeltas į naują vietą. Paprasčiausiai pridėkite 301 nukreipimą dubliuojamame turinyje, kad lankytojai būtų nukreipti į originalų turinį.
- Pridėti rel="canonical" žymą - Ši žyma yra "meta" 301 nukreipimo versija. Žyma "rel=canonical" nurodo "Google", kuris yra originalus konkretaus puslapio URL:
//example.com/original-page.html " rel="canonical" />
Praneša "Google", kad puslapis - original-page.html - yra dubliuojamo puslapio "originali" versija. Jei naudojate "WordPress", šią žymą lengva pridėti naudojant "Yoast SEO" arba "All in One SEO".
Jei norite, kad lankytojai galėtų pasiekti besidubliuojantį turinį, naudokite rel="canonical" žyma. Jei nenorite, kad lankytojai ar robotai pasiektų turinį, naudokite 301 nukreipimą.
Būkite atsargūs, nes jie turės įtakos jūsų SEO optimizavimui.
Perduota jums
Robots.txt failas yra naudingas sąjungininkas, padedantis nustatyti, kaip paieškos sistemų vorai ir kiti robotai sąveikauja su jūsų svetaine. Tinkamai naudojamas, jis gali turėti teigiamos įtakos jūsų pozicijoms ir palengvinti svetainės nuskaitymą.
Naudodamiesi šiuo vadovu suprasite, kaip veikia "Robots.txt", kaip jis įdiegiamas ir kai kuriuos dažniausiai pasitaikančius jo naudojimo būdus. Ir venkite bet kurios iš anksčiau aptartų klaidų.
Susijęs skaitymas:
- Geriausi rangų stebėjimo įrankiai tinklaraštininkams, palyginti
- Galutinis "Google" nuorodų gidas
- 5 galingų raktinių žodžių tyrimo įrankių palyginimas
